
J’ai beaucoup aimé écrire des conseils courts (et parfois un peu plus longs) pour mon sujet #GTMTips. Avec l’avènement de Google Analytics : App + Web et en particulier la possibilité d’accéder à des données brutes via BigQuery, j’ai pensé que c’était le bon moment pour commencer un nouveau sujet de conseil : #BigQueryTips.
Pour Universal Analytics, l’accès à l’exportation BigQuery avec Google Analytics 360 a été l’un des principaux arguments de vente de la plate-forme coûteuse. L’approche hybride d’accès à cru les données qui ont néanmoins été annotées avec le schéma de mise en session de Google Analytics et toutes les intégrations (par exemple, Google Ads) que l’utilisateur aurait pu activer sont en effet une chose puissante.
Avec Google Analytics : Application + Webla plateforme s’éloigne du modèle de données qui existait depuis l’époque d’Urchin, et converge plutôt vers Firebase Analytics, auquel nous avons déjà eu accès avec des applications natives Android et iOS.

Heureusement, l’exportation BigQuery pour les propriétés Application + Web n’entraîne aucun coût de plate-forme supplémentaire : vous ne payez que pour le stockage et les requêtes, comme vous le feriez si vous créiez vous-même un projet BigQuery sur la plate-forme cloud de Google.
Ainsi, avec les données circulant dans BigQuery, j’ai pensé qu’il était temps de commencer à écrire sur la façon de créer des requêtes sur ce magasin de données en colonnes. L’une des raisons est que je veux me mettre au défi, mais l’autre raison est qu’il n’y a tout simplement pas beaucoup d’informations disponibles en ligne lorsqu’il s’agit d’utiliser SQL avec les exportations BigQuery de Firebase Analytics.

Pour commencer avec ce nouveau sujet, j’ai demandé l’aide de mon assistant SQL préféré dans #measure, Pawel Kapuscinski. Il n’est jamais à court de solution lorsque des questions BigQuery délicates apparaissent dans Measure Slack. J’ai donc pensé qu’il serait formidable de le faire contribuer avec certains de ses conseils préférés sur la façon d’aborder l’interrogation des données BigQuery avec SQL.
Avec un peu de chance, #BigQueryTips s’étendra à plus d’articles à l’avenir. Il y a certainement beaucoup de chemin à parcourir !
Commencer
Tout d’abord, vous aurez naturellement besoin d’un Google Analytics : Application + Web biens. Voici quelques guides pour commencer :
- Étape par étape : Configurer une propriété Application + Web (Krista Seiden)
- Premiers pas avec Google Analytics : Application + Web (Simo)
- Guide d’instrumentation et balise App + Web Properties (Google)
Ensuite, vous devez activer l’exportation BigQuery pour la nouvelle propriété, et pour cela, vous devez suivre ce guide.

Une fois que l’exportation est opérationnelle, c’est le bon moment pour prendre un moment pour apprendre et/ou se rafraîchir la mémoire sur le fonctionnement de SQL. Pour cela, il n’existe aucun autre didacticiel en ligne qui se rapproche le plus du didacticiel SQL interactif gratuit de Mode Analytics.

Et une fois que vous avez appris la différence entre LEFT JOIN et CROSS JOIN, vous pouvez consulter certains des exemples d’ensembles de données pour iOS Firebase Analytics et Android Firebase Analytics. Jouez avec eux, en essayant de comprendre à quel point l’interrogation d’une base de données relationnelle typique diffère de l’accès aux données stockées dans une structure en colonnes comme le fait BigQuery.
À ce stade, votre table BigQuery doit collecter des vidages de données quotidiens à partir du Application + Web balises se déclenchent sur votre site, alors travaillons avec Pawel et introduisons quelques éléments très utiles Requêtes SQL BigQuery pour commencer sur ce chemin d’analyse de données !
Conseil n° 1 : CASE et GROUP BY
Notre premier conseil porte sur deux instructions SQL extrêmement utiles : CASE et GROUP BY. Utilisez-les pour agréger et regrouper vos données !
CAS
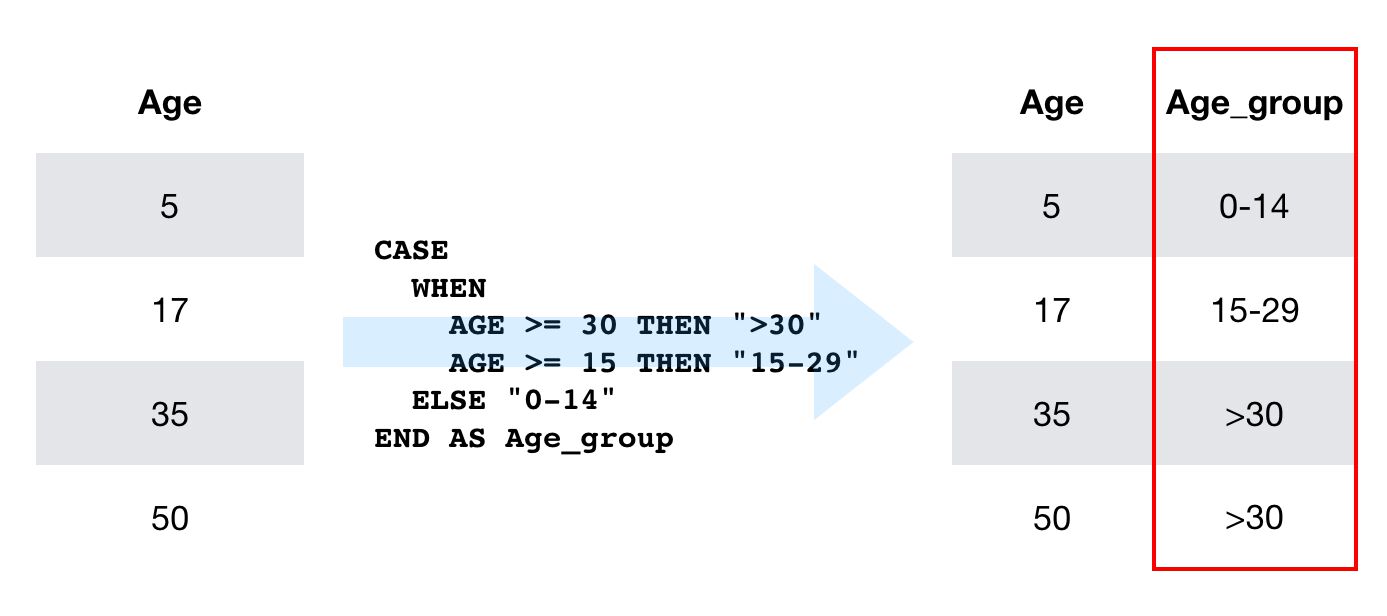
CASE déclarations sont similaires à la if...else déclarations utilisées dans d’autres langues. La condition est introduite avec la WHEN mot-clé, et le premier WHEN condition qui correspond aura son THEN valeur renvoyée comme valeur pour cette colonne.
Vous pouvez utiliser le ELSE mot-clé à la fin pour spécifier une valeur par défaut. Si ELSE n’est pas défini et qu’aucune condition n’est remplie, la colonne prend la valeur null.
TABLEAU DES SOURCES
| utilisateur | âge |
|---|---|
| 12345 | 15 |
| 23456 | 54 |
SQL
SELECT user, age, CASE WHEN age >= 90 THEN "90+" WHEN age >= 50 THEN "50-89" WHEN age >= 20 THEN "20-49" ELSE "0-19" END AS age_bucket FROM some_tableRÉSULTAT DE LA REQUÊTE
| utilisateur | âge | age_bucket |
|---|---|---|
| 12345 | 15 | 0-19 |
| 23456 | 54 | 50-89 |
Les CASE est utile pour les transformations rapides et pour agréger les données en fonction de conditions simples.
PAR GROUPE
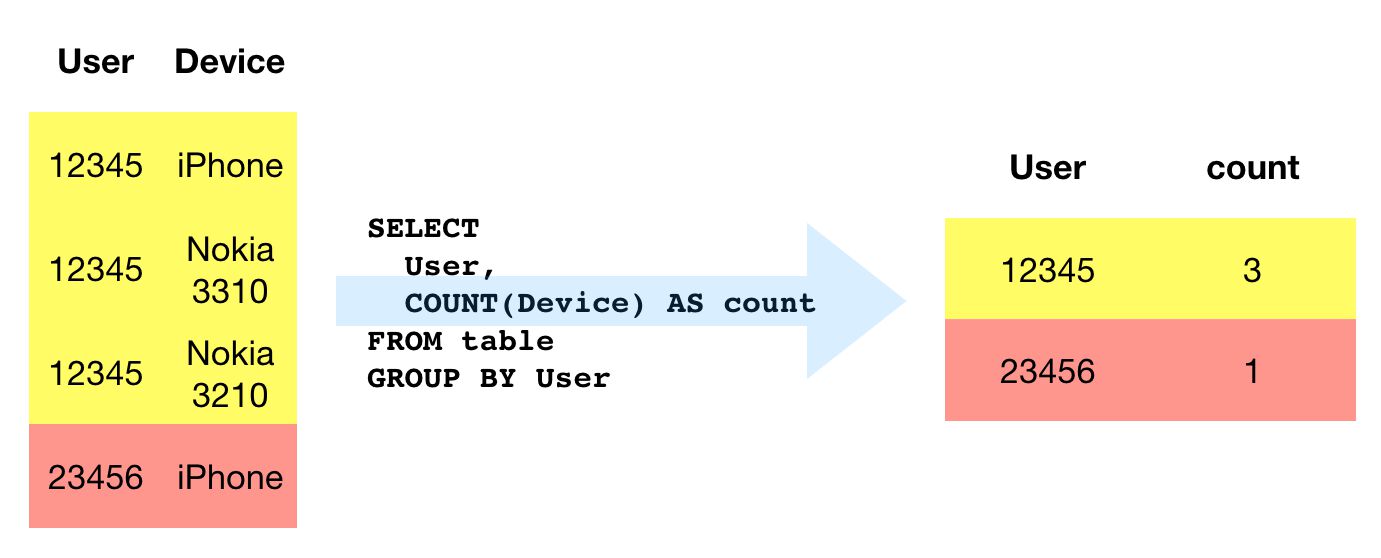
GROUP BY est nécessaire chaque fois que vous voulez résumer vos données. Par exemple, lorsque vous faites des calculs avec COUNT (pour renvoyer le nombre d’instances) ou SUM (pour renvoyer la somme des instances), vous devez indiquer une colonne pour regrouper ces calculs (sauf si vous êtes seul récupération de la colonne calculée) . GROUP BY est donc le plus souvent utilisé avec des fonctions d’agrégation telles que COUNT, MAX, ANY_VALUE, SUMet AVG. Il est également utilisé avec certaines fonctions de chaîne telles que STRING_AGG lors de l’agrégation de plusieurs lignes en une seule chaîne.
TABLEAU DES SOURCES
| utilisateur | mobile_device_model |
|---|---|
| 12345 | iPhone 5 |
| 12345 | Nokia 3310 |
| 23456 | iPhone 7 |
SQL
SELECT user, COUNT(mobile_device_model) AS device_count FROM table GROUP BY 1RÉSULTAT DE LA REQUÊTE
| utilisateur | device_count |
|---|---|
| 12345 | 2 |
| 23456 | 1 |
Dans la requête ci-dessus, nous supposons qu’un seul utilisateur peut être associé à plusieurs appareils dans la table interrogée. Comme on fait un COUNT de tous les appareils pour un utilisateur donné, nous devons regrouper les résultats par user colonne pour que la requête fonctionne.
CAS D’UTILISATION : Répartition des catégories d’appareils entre les utilisateurs
Gardons un instant le thème des utilisateurs et des appareils.
Utilisateurs et événements sont les métriques clés pour App + Web. Ceci est fondamentalement différent du sessionapproche centrée de Google Analytics (même s’il y a aussi des réverbérations de “sessions” dans App + Web). C’est beaucoup plus proche d’un vrai frapper le flux modèle qu’avant.
Cependant, l’événement compte à lui seul pour ne rien dire sans que nous approfondissions quel genre d’événement s’est produit.
Dans ce premier conseil, nous allons apprendre à calculer le nombre d’utilisateurs par catégorie d’appareil. Étant donné que le concept d'”utilisateur” est toujours lié à un identifiant client de navigateur unique, si la même personne visitait le site Web sur deux instances ou appareils de navigateur différents, elle serait comptée comme deux utilisateurs.
Voici à quoi ressemble la requête :
SELECT CASE WHEN device.category = "desktop" THEN "desktop" WHEN device.category = "tablet" AND app_info.id IS NULL THEN "tablet-web" WHEN device.category = "mobile" AND app_info.id IS NULL THEN "mobile-web" WHEN device.category = "tablet" AND app_info.id IS NOT NULL THEN "tablet-app" WHEN device.category = "mobile" AND app_info.id IS NOT NULL THEN "mobile-app" END AS device, COUNT(DISTINCT user_pseudo_id) AS users FROM `dataset.analytics_accountId.events_2*` GROUP BY 1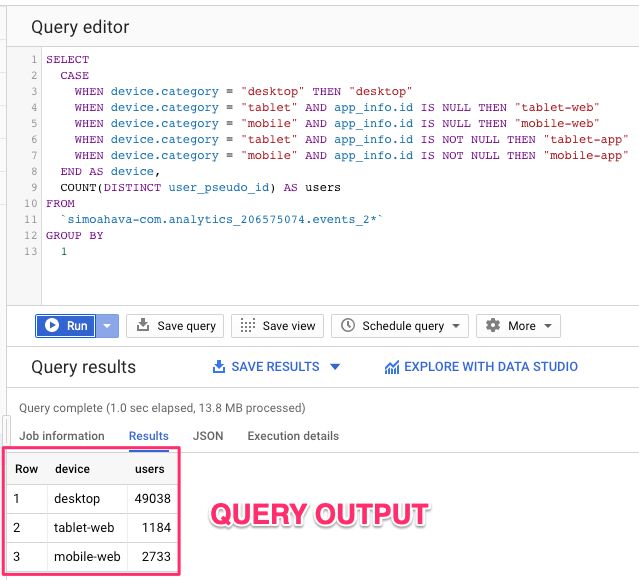
La requête elle-même est simple, mais elle utilise efficacement les deux instructions abordées dans ce chapitre. CASE est utilisé pour segmenter davantage les utilisateurs “mobiles” et “tablettes” en groupes Web et applications (ce qui vous sera utile une fois que vous commencerez à collecter des données à partir de sites Web et d’applications mobiles), et GROUP BY affiche le nombre d’ID d’appareils uniques par catégorie d’appareils.
Astuce #2 : DISTINCT et AYANT
Les deux prochains mots clés que nous aborderons sont HAVING et DISTINCT. Le premier est idéal pour filtrer les résultats en fonction de valeurs agrégées. Ce dernier est utilisé pour dédupliquer les résultats afin d’éviter de calculer plusieurs fois le même résultat.
DISTINCT

Les DISTINCT mot-clé est utilisé pour dédupliquer les résultats.
TABLEAU DES SOURCES
| utilisateur | device_category | ID de session |
|---|---|---|
| 12345 | bureau | abc123 |
| 12345 | bureau | def234 |
| 12345 | tablette | efg345 |
| 23456 | portable | fgh456 |
SQL
SELECT user, COUNT(DISTINCT device_category) AS device_category_count FROM table GROUP BY 1RÉSULTAT DE LA REQUÊTE
| utilisateur | device_category_count |
|---|---|
| 12345 | 2 |
| 23456 | 1 |
Par exemple, si l’utilisateur a eu trois sessions avec des catégories d’appareils desktop, desktopet tabletpuis une requête pour COUNT(DISTINCT device.category) retournerais 2car il n’y a que deux instances de distinct catégories d’appareils.
AYANT
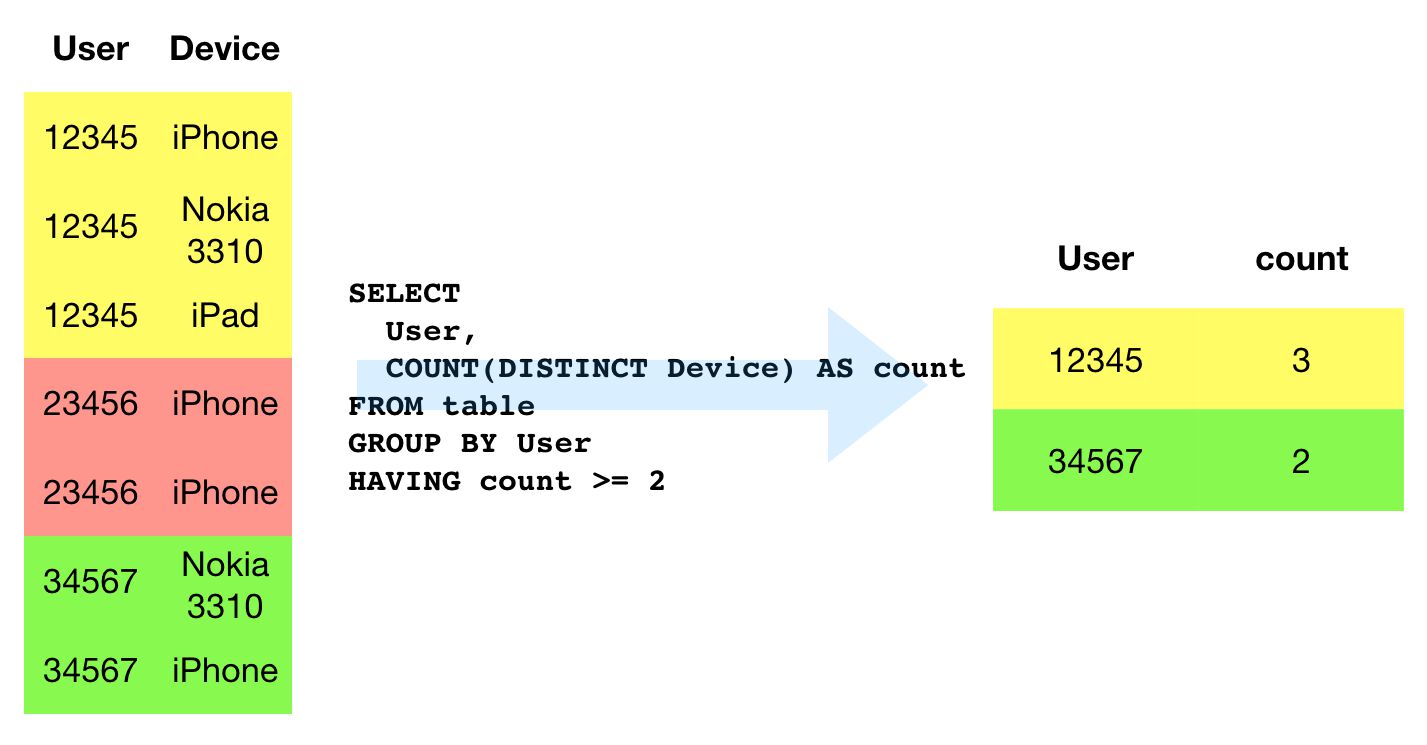
Les HAVING La clause peut être utilisée à la fin de la requête, une fois tous les calculs effectués, pour filtrer les résultats. Toutes les lignes sélectionnées pour la requête sont toujours traitées, même si le HAVING L’instruction supprime certains d’entre eux de la table de résultats.
TABLEAU DES SOURCES
| utilisateur | device_category | ID de session |
|---|---|---|
| 12345 | bureau | abc123 |
| 12345 | bureau | def234 |
| 12345 | tablette | efg345 |
| 23456 | portable | fgh456 |
SQL
SELECT user, COUNT(DISTINCT device_category) AS device_category_count FROM table GROUP BY 1 HAVING device_category_count > 1RÉSULTAT DE LA REQUÊTE
| utilisateur | device_category_count |
|---|---|
| 12345 | 2 |
C’est semblable à WHERE (voir chapitre suivant), mais contrairement WHERE qui est utilisé pour filtrer les enregistrements réels qui sont traités par la requête, HAVING est utilisé pour filtrer sur des valeurs agrégées. Dans la requête ci-dessus, device_category_count est un décompte agrégé de toutes les catégories d’appareils distinctes trouvées dans l’ensemble de données.
CAS D’UTILISATION : catégories d’appareils distinctes par utilisateur
Depuis le nom même, Application + Webimplique une mesure multi-appareils, il semble fructueux d’explorer certaines manières de regrouper et de filtrer les données en fonction des utilisateurs utilisant plusieurs appareils.
La requête est similaire à celle du chapitre précédent, mais cette fois au lieu de regrouper par catégorie d’appareil, nous regroupons par utilisateur et comptons le nombre de catégories d’appareils uniques avec lesquelles chaque utilisateur a visité le site. Nous filtrons les données pour inclure uniquement les utilisateurs avec plus d’une catégorie d’appareils dans l’ensemble de données.
Il s’agit d’une requête exploratoire. Vous pouvez ensuite l’étendre pour détecter différents modèles au lieu d’utiliser simplement la catégorie d’appareils. La catégorie d’appareil est une dimension inconstante à utiliser, comme dans l’exemple de jeu de données utilisé pour cet article, plusieurs fois un appareil étiqueté comme “Apple iPhone” était en fait compté comme un appareil de bureau.
Consultez cet article de Craig Sullivan pour comprendre à quel point l’attribution d’appareils dans l’analyse Web est un problème.
SELECT user_pseudo_id, COUNT(DISTINCT device.category) AS used_devices_count, STRING_AGG(DISTINCT device.category) AS distinct_devices, STRING_AGG(device.category) AS devices FROM `dataset.analytics_accountId.events_2*` GROUP BY 1 HAVING used_devices_count > 1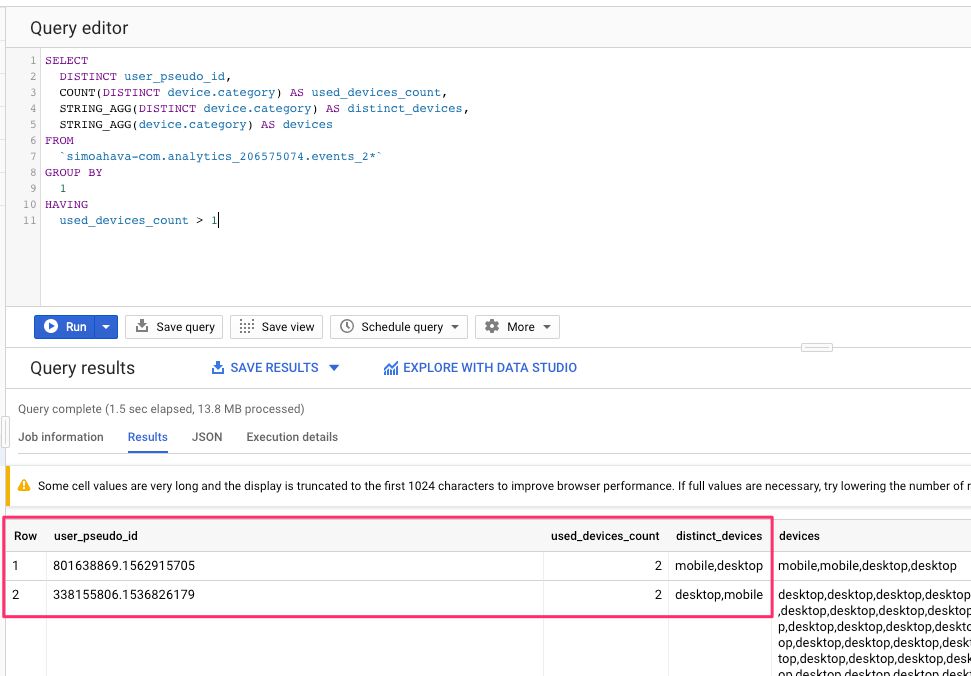
En prime, vous pouvez voir comment STRING_AGG peut être utilisé pour concaténer plusieurs valeurs dans une seule colonne. Ceci est utile pour identifier les modèles qui émergent sur plusieurs lignes de données !
Astuce #3 : OÙ
OÙ
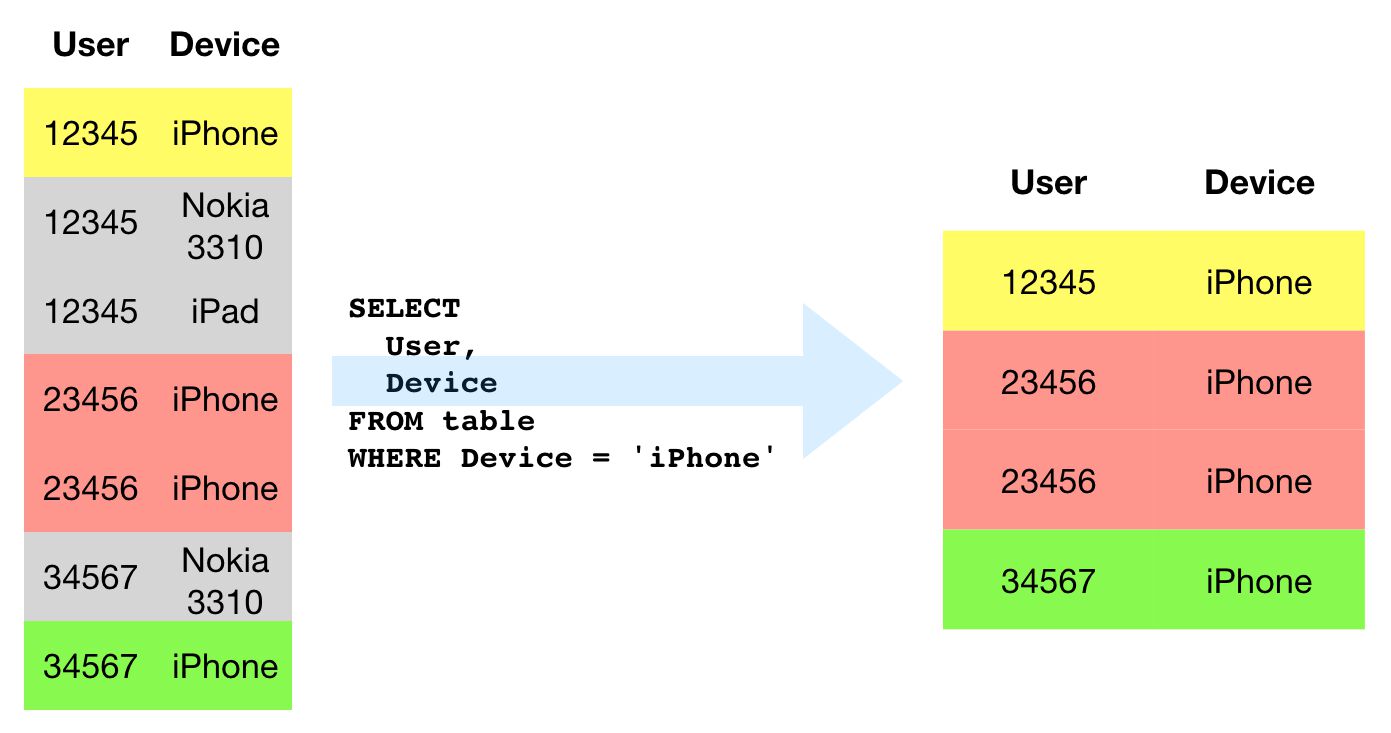
Si vous souhaitez filtrer les enregistrements sur lesquels vous allez exécuter votre requête, WHERE Est ton meilleur ami. Comme il filtre les enregistrements qui sont traités, c’est aussi un excellent moyen de réduire le coût (performance et monétaire) de vos requêtes.
TABLEAU DES SOURCES
| utilisateur | ID de session | landing_page_path |
|---|---|---|
| 12345 | abc123 | /domicile/ |
| 12345 | bcd234 | /achat/ |
| 23456 | cde345 | /domicile/ |
| 34567 | def456 | /Nous contacter/ |
SQL
SELECT * FROM table WHERE user = '12345'RÉSULTAT DE LA REQUÊTE
| utilisateur | ID de session | landing_page_path |
|---|---|---|
| 12345 | abc123 | /domicile/ |
| 12345 | bcd234 | /achat/ |
Les WHERE La clause est utilisée pour filtrer les lignes sur lesquelles le reste de la requête est effectué. Il est introduit directement après le FROM déclaration, et il se lit comme “retourne toutes les lignes dans le FROM table qui correspondent à l’état du WHERE clause”.
Notez que WHERE ne peut pas être utilisé avec des valeurs agrégées. Donc, si vous avez effectué des calculs avec les lignes renvoyées par la table, vous devez utiliser HAVING au lieu.
En raison de ce, WHERE est moins coûteux en termes de traitement des requêtes que HAVING.
CAS D’UTILISATION : utilisateurs engagés
Comme mentionné précédemment, Application + Web est piloté par les événements. Avec Firebase Analytics, Google a introduit un certain nombre d’événements prédéfinis collectés automatiquement pour aider les utilisateurs à collecter des données utiles à partir de leurs applications et sites Web sans avoir à fléchir un seul muscle.
Un tel événement est engagement_utilisateur. Ceci est déclenché lorsque l’utilisateur a interagi avec le site Web ou l’application pendant une période de temps spécifiée.
Étant donné que cela est facilement disponible en tant qu’événement personnalisé, nous pouvons créer une requête simple qui utilise le WHERE clause pour renvoyer uniquement les enregistrements où l’utilisateur a été engagé.
La clé pour WHERE est qu’il est exécuté après le FROM clause (qui spécifie la table à interroger). Si une ligne ne correspond pas à la condition dans WHEREil ne sera pas utilisé pour faire correspondre le reste de la requête.
SELECT event_date, COUNT(DISTINCT user_pseudo_id) AS engaged_users FROM `dataset.analytics_accountId.events_20190922` WHERE event_name = "user_engagement" GROUP BY 1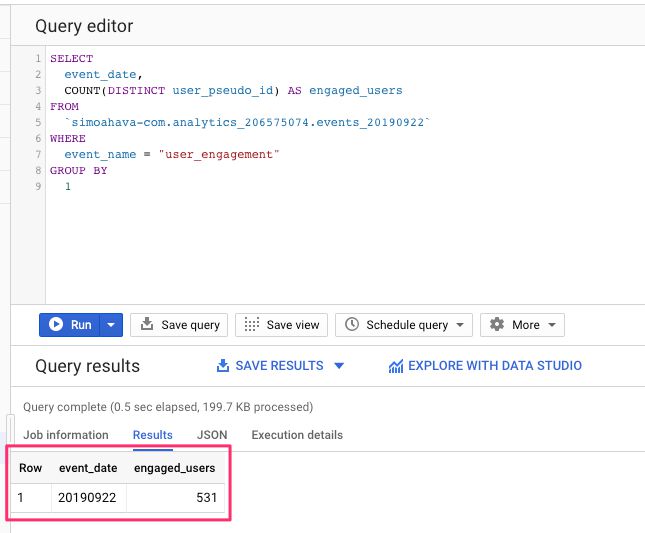
Vous voyez comment nous incluons les données d’une seule date ? Nous n’incluons également que DISTINCT utilisateurs, donc si un utilisateur a été engagé plus d’une fois au cours de la journée, nous ne le comptons qu’une seule fois.
Astuce n°4 : SOUS-REQUETES et fonctions ANALYTIQUES
UN sous-requête en SQL signifie une requête dans une requête. Ils peuvent émerger à plusieurs endroits différents, comme dans SELECT clauses, FROM clauses, et WHERE clauses.
Analytique les fonctions vous permettent d’effectuer des calculs qui couvrent autre rangées que celle qui est en cours de traitement. C’est similaire à des agrégations telles que SUM et AVG sauf qu’il n’en résulte pas que les lignes soient regroupées en un seul résultat. C’est pourquoi les fonctions analytiques sont parfaitement adaptées à des choses comme totaux cumulés/moyennes ou, dans des contextes analytiques, déterminer les limites de session en examinant les premier et dernier horodatages, par exemple.
SOUS-REQUETE

Le but d’une sous-requête est d’exécuter des calculs sur des données de table et de renvoyer le résultat de ces calculs à la requête englobante. Cela vous permet d’organiser logiquement vos requêtes, et cela permet de faire des calculs sur calculs, ce qui ne serait pas possible dans une seule requête.
TABLEAU DES SOURCES
| utilisateur | Nom de l’événement |
|---|---|
| 12345 | session_start |
| 23456 | engagement_utilisateur |
| 34567 | engagement_utilisateur |
| 45678 | lien_clic |
SQL
SELECT COUNT(DISTINCT user) AS all_users, ( SELECT COUNT(DISTINCT user) FROM table WHERE event_name = 'user_engagement' ) AS engaged_users FROM tableRÉSULTAT DE LA REQUÊTE
| tous les utilisateurs | utilisateurs engagés |
|---|---|
| 4 | 2 |
Dans cet exemple, la sous-requête se trouve dans le SELECT ce qui signifie que le résultat de la sous-requête est regroupé dans une seule colonne de la requête principale.
Ici le engaged_users récupère le nombre de tous les ID utilisateur distincts de la table, où ces utilisateurs avaient un événement nommé user_engagement collectées à tout moment.
La requête principale combine ensuite cela avec un décompte de tous les ID utilisateur distincts sans aucune restriction, et vous obtenez ainsi les deux décomptes dans la même table.
Vous n’auriez pas pu y parvenir avec la requête principale uniquement, car le WHERE déclaration s’applique à tous SELECT colonnes du tableau. C’est pourquoi nous avions besoin de la sous-requête – nous devions utiliser un WHERE déclaration qui ne s’appliquait qu’aux engaged_users colonne.
FONCTIONS ANALYTIQUES
Les fonctions analytiques peuvent être très difficiles à comprendre, car avec SQL, vous avez l’habitude de parcourir la table ligne par ligne et de comparer la requête à chaque ligne une par une.
Avec une fonction analytique, vous étirez un peu cette logique. La requête parcourt toujours la table source ligne par ligne, mais cette fois, vous pouvez référencer d’autres lignes lors des calculs.
TABLEAU DES SOURCES
| utilisateur | Nom de l’événement | événement_horodatage |
|---|---|---|
| 12345 | Cliquez sur | 1001 |
| 12345 | Cliquez sur | 1002 |
| 23456 | session_start | 1012 |
| 23456 | engagement_utilisateur | 1009 |
| 34567 | Cliquez sur | 1000 |
SQL
SELECT event_name, user, event_timestamp FROM ( SELECT user, event_name, event_timestamp, RANK() OVER (PARTITION BY event_name ORDER BY event_timestamp) AS rank FROM table ) WHERE rank = 1RÉSULTAT DE LA REQUÊTE
| Nom de l’événement | utilisateur | événement_horodatage |
|---|---|---|
| Cliquez sur | 34567 | 1000 |
| engagement_utilisateur | 23456 | 1009 |
| session_start | 23456 | 1012 |
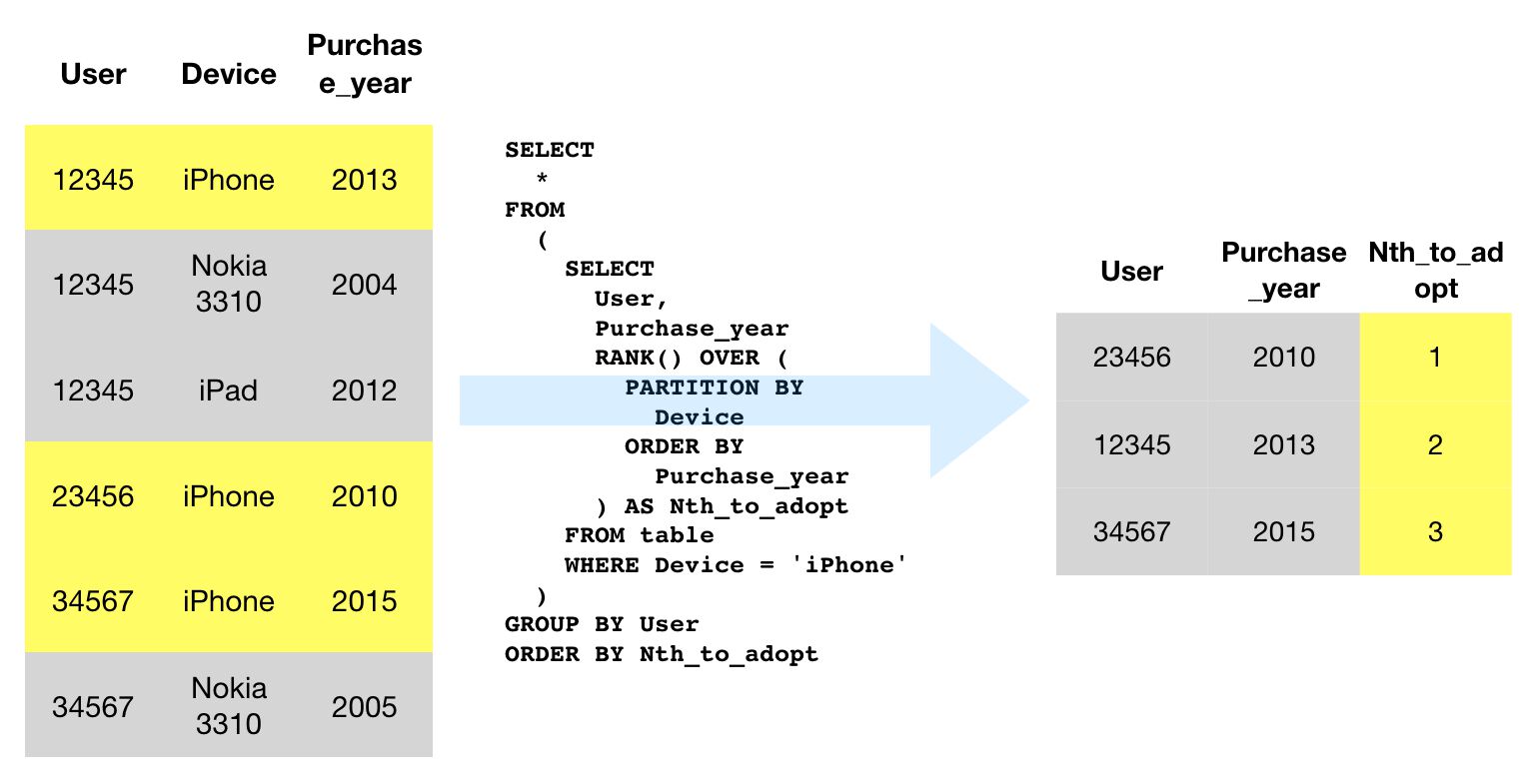
Dans cette requête, nous prenons chaque événement et voyons quel utilisateur a envoyé le première tel événement dans le tableau.
Pour chaque ligne du tableau, le RANK() OVER (PARTITION BY event_name ORDER BY event_timestamp) AS rank est exécuté. Les cloison est essentiellement une table de « référence » avec tous les noms d’événements correspondant au nom d’événement de la ligne actuelle, et leurs horodatages respectifs.
Ces horodatages sont ensuite classés par ordre croissant (au sein de la partition). Les RANK() OVER une partie de la fonction renvoie le nom de l’événement actuel rang dans ce tableau.
Pour parcourir un exemple, supposons que le moteur de requête rencontre la première ligne de la table. Les RANK() OVER (PARTITION BY event_name ORDER BY event_timestamp) crée la table de référence qui ressemble à ceci pour la première ligne :
| utilisateur | Nom de l’événement | événement_horodatage | rang |
|---|---|---|---|
| 12345 | Cliquez sur | 1000 | 1 |
| 12345 | Cliquez sur | 1001 | 2 |
| 12345 | Cliquez sur | 1002 | 3 |
La requête vérifie ensuite comment la ligne actuelle correspond à cette partition et renvoie 2 car la première ligne du tableau était le rang 2 de sa partition.
Cette partition est éphémère – c’est seul utilisé pour calculer le résultat de la fonction analytique.
Pour les besoins de cet exercice, cette fonction d’analyse est en outre effectuée dans une sous-requête, de sorte que la requête principale peut filtrer le résultat à l’aide d’un WHERE uniquement pour les éléments qui avaient un rang 1 (premier horodatage d’un événement donné).
Je vous recommande de consulter les premiers paragraphes de ce document – ils expliquent comment fonctionne le partitionnement.
CAS D’UTILISATION : Première interaction par événement
Étendons l’exemple ci-dessus dans l’ensemble de données App + Web.
Nous allons créer une liste d’ID client avec le nom de l’événement, l’horodatage et l’horodatage converti dans un format lisible (date).
SELECT user_pseudo_id, event_name, event_timestamp, DATETIME(TIMESTAMP_MICROS(event_timestamp), "Europe/Helsinki") AS date FROM ( SELECT user_pseudo_id, event_name, event_timestamp, RANK() OVER (PARTITION BY event_name ORDER BY event_timestamp) AS rank FROM `dataset.analytics_accountId.events_20190922` ) WHERE rank = 1 ORDER BY event_timestamp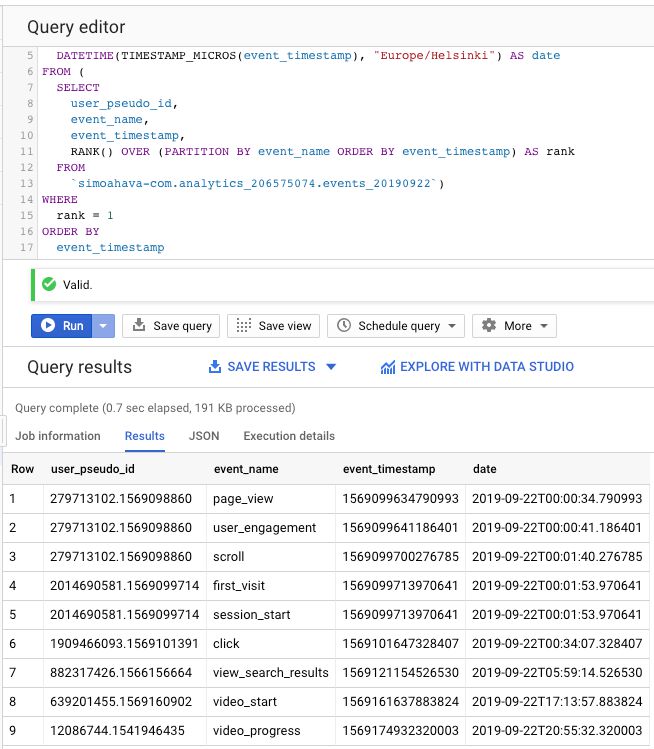
La logique est exactement la même que dans l’introduction aux fonctions analytiques ci-dessus. La seule différence est la façon dont nous utilisons le DATETIME et TIMESTAMP_MICROS pour transformer l’horodatage UNIX (stocké dans BigQuery) en un format de date lisible.
Ne vous inquiétez pas – les fonctions analytiques en particulier sont un concept difficile à comprendre. Jouez avec les différentes fonctions analytiques pour avoir une idée de la façon dont elles fonctionnent avec l’idée source.
Il existe de nombreux articles et vidéos en ligne qui expliquent davantage le concept, je vous recommande donc de consulter le Web pour plus d’informations. Nous reviendrons également très souvent sur les fonctions analytiques dans les prochains articles #BigQueryTips.
Astuce #5 : UNNEST et CROSS JOIN
Le jeu de données exporté par App + Web ne se retrouve pas dans une base de données relationnelle où nous pourrions utiliser le JOIN clé pour extraire rapidement des informations supplémentaires sur les pages, les sessions et les utilisateurs.
Au lieu de cela, BigQuery organise les données dans des champs imbriqués et répétés – c’est ainsi qu’une seule ligne peut représenter tous les appels d’une session (comme dans l’ensemble de données Google Analytics).
Le problème avec cette approche est qu’il n’est pas trop intuitif d’accéder à ces valeurs imbriquées.
Entrer UNNESTen particulier lorsqu’il est associé à CROSS JOIN.
UNNEST signifie que la structure imbriquée est en fait développée afin que chaque élément à l’intérieur puisse être joint au reste des colonnes de la ligne. Il en résulte que la ligne unique devient plusieurs lignes, où chaque ligne correspond à une valeur dans la structure imbriquée. Cette colonne à lignes est réalisée avec un CROSS JOINoù chaque élément de la structure non imbriquée est joint à chaque colonne du reste du tableau.
UNNEST et CROSS JOIN
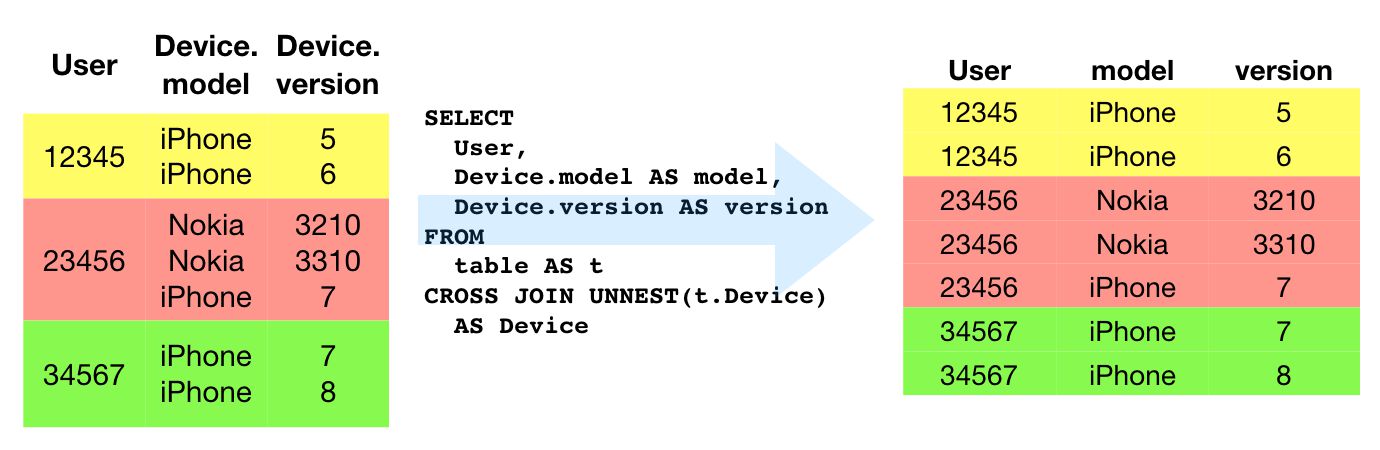
Les deux mots-clés vont intrinsèquement ensemble, donc…




