
Il est de nouveau temps pour MeasureCamp ! Comme avant, j’ai envie d’écrire un article d’accompagnement pour ma session, car il y a toujours tellement plus à dire que le créneau horaire ne le permet. Ainsi, le sujet de cet article est le modèle de données utilisé par Google Tag Manager pour traiter les données numériques dans votre couche de données.
Ce message reprend également là où j’étais parti lors de ma précédente incursion dans la couche de données. Cependant, là où le premier article visait à être générique (puisque la couche de données devrait être générique), cet article examinera comment GTM utilise les informations de la couche de données génériques et comment il traite ces informations pour fonctionner avec les fonctionnalités propriétaires du outil.
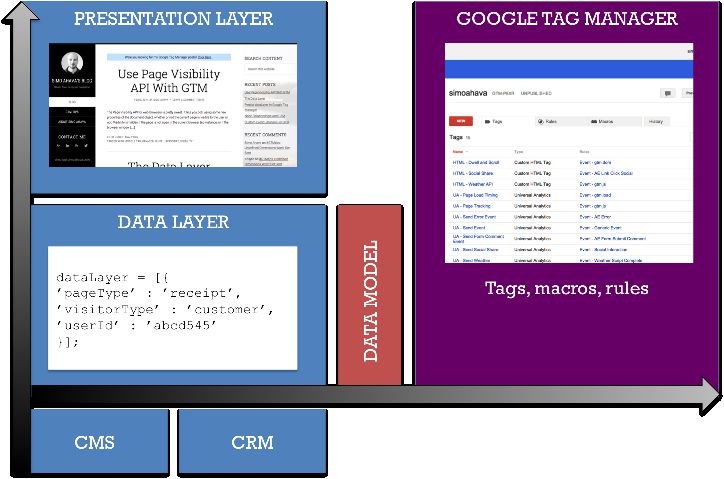
Le diagramme ci-dessus devrait élucider mon propos (craignez mes compétences PowerPoint en image).
Nous avons des données qui transitent par vos systèmes backend vers votre site Web. Certaines de ces données sont utilisées pour construire le site Web avec ses visuels et ses fonctionnalités, et certaines de ces données sont stockées dans la couche de données pour être utilisées par d’autres outils et applications connectés au site Web.
Google Tag Manager n’accède pas directement à la structure de la couche de données, car cela compromettrait l’objectif générique et indépendant de l’outil de la couche de données. Au lieu de cela, il extrait les données de la couche de données, les stocke dans son modèle de données abstrait interne et utilise ce pour traiter les données numériques.
Puisque nous vivons dans un monde multi-fournisseurs, où les outils et applications Web poussent comme des champignons après la pluie, il est important de respecter la couche de données génériques. C’est à la sophistication de l’outil lui-même d’utiliser ces données, mais cela doit être fait de manière non invasive – en utilisant des méthodes pull plutôt que push.
| dataLayer | Modèle de données |
|---|---|
| Outil indépendant | Spécifique à l’outil |
| Générique | Unique |
| Accédé directement | Accessible via l’assistant |
| Structuré | Abstrait |
Il y a une différence entre la couche de données et le modèle de données. Pour certains, cela peut sembler très subtil, mais en réalité, c’est ce qui garantit que la couche de données reste un conteneur de données standardisé et gratuit. Le modèle de données, en revanche, est construit selon les spécifications propres à chaque plate-forme, mais la façon dont il communique avec la couche de données doit être propre et peut-être même standardisée, car c’est la seule façon de garantir qu’un seul outil ne ruine pas la couche de données pour tous.
Mise en place de l’épreuve
Le moyen le plus courant d’accéder au modèle de données de GTM consiste à utiliser la macro variable de la couche de données. Lorsque vous appelez ce type de macro, voici ce qui se passe :
-
La macro interroge le modèle de données via une méthode d’interface
-
Si une clé avec le nom de variable donné est trouvée, sa valeur est renvoyée
-
Si aucune clé n’est trouvée,
undefinedest retourné à la place
Pour les besoins de cet article, je vais maintenant créer un testeur, qui vous montre comment fonctionne le modèle de données. Le testeur est une balise HTML personnalisée qui se déclenche lors d’un certain événement (‘dlTest’). Lorsqu’il se déclenche, il imprime le contenu de la macro de variable de couche de données dans la console JavaScript.

La macro elle-même n’est qu’une macro de couche de données qui fait référence au nom de la variable testKey:
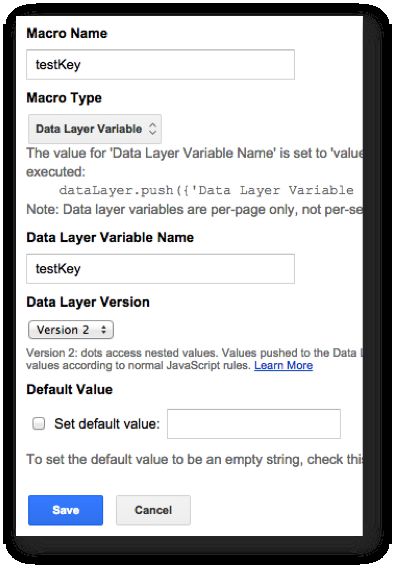
Alors maintenant, chaque fois que je veux voir quelle est la clé testKey contient dans le modèle de données, je n’ai qu’à taper ce qui suit dans la console :
dataLayer.push({'event' : 'dlTest'});
Ensuite, je publierai mon conteneur et j’essaierai ceci. Voici à quoi ressemble la console maintenant si j’exécute l’événement :
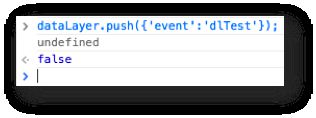
Le undefined est ce que la macro renvoie réellement. faux est renvoyé car l’envoi de l’événement a déclenché une balise.
Ajouter et modifier la clé
Commençons simple. Je vais ajouter quelques valeurs à la clé et voir comment la macro réagit :

Voici les poussées dans l’ordre :
-
'string'– chaîne de caractères -
1– Numéro -
[1, 2, 3]- Déployer -
{'key' : 'value'}– objet -
true– booléen -
function() { return undefined; }– une fonction
Comme vous pouvez le voir, l’interface get() La fonction ne renvoie que la dernière valeur. dataLayercependant, contient toutes les valeurs :

Voici les principaux plats à emporter:
-
Le modèle de données n’est pas la même chose que la couche de données. Toutes les valeurs que j’ai poussées ci-dessus peuvent être trouvées dans la couche de données, mais seule la valeur la plus récente est stockée dans le modèle de données
-
Lorsque vous poussez une valeur de type différent, la valeur précédente est complètement écrasée dans le modèle de données
C’est assez simple, non ? Eh bien, essayons de mettre à jour la valeur avec une autre valeur de du même type suivant.
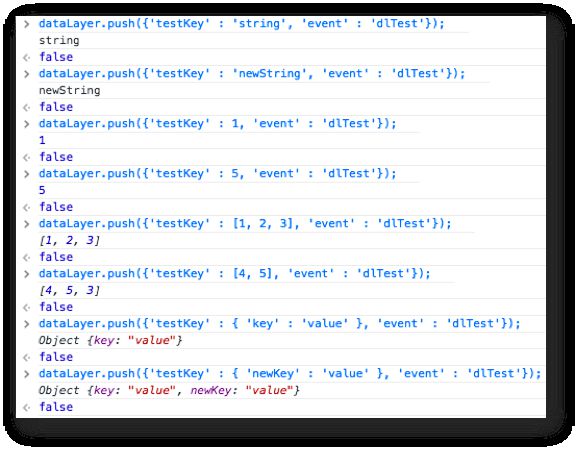
Voici les poussées dans l’ordre :
-
'string'+'newString'=>'newString' -
1+5=>5 -
[1, 2, 3]+[4, 5]=>[4, 5, 3]*HEIN? -
{'key' : 'value'}+{'newKey' : 'value'}=>{'key' : 'value', 'newKey' : 'value'}*WTF ?
Les valeurs primitives fonctionnent comme prévu. Pousser une autre valeur du même type écrase simplement la valeur précédente. Cependant, le tableau et l’objet ordinaire se comportent très étrangement.
En effet, lorsque vous placez un tableau au-dessus d’un tableau ou un objet ordinaire au-dessus d’un objet ordinaire, l’interface effectue une fusion récursive. Autrement dit, il vérifie si les clés de l’objet ou du tableau qui sont poussées existent déjà. Si tel est le cas, leurs valeurs sont mises à jour, mais toutes les autres clés sont laissées telles quelles.
C’est facile à comprendre si vous regardez comment se comporte l’objet ordinaire.
Tout d’abord, vous poussez un objet avec la clé ‘clé’ avec la valeur ‘évaluer’. Ensuite, vous poussez un objet avec la clé ‘nouvelle clé’ avec la valeur ‘évaluer’. Maintenant, ‘clé’ n’est pas la même chose que ‘nouvelle clé’donc l’objet ordinaire est mis à journon remplacé.
Mais qu’en est-il de l’Array ? je pousse [4, 5]qui n’ont rien à voir avec [1, 2, 3]. Le résultat final ne devrait-il pas être
[4, 5]ou alors
[1, 2, 3, 4, 5]ou même
[[1, 2, 3], [4, 5]]?
Sûrement [4, 5, 3] est un bogue?
Non, si vous connaissez votre JavaScript. Un tableau est un type d’objet. Il possède également des clés avec lesquelles vous pouvez accéder aux valeurs qu’il contient. Les clés commencent à 0 et augmentent jusqu’à ce qu’il n’y ait plus de membres dans le tableau. Ainsi, le premier Array ressemble en fait à ceci :
[1, 2, 3]
Clé 0 : Valeur 1 Clé 1 : Valeur 2 Clé 2 : Valeur 3
Le deuxième tableau ressemble à ceci :
[4, 5]
Clé 0 : Valeur 4 Clé 1 : Valeur 5
Désormais, la fusion récursive repère ces clés partagées (0 et 1) et met à jour leurs valeurs en conséquence. La troisième touche (2) n’est pas touchée, car le tableau qui a été poussé en deuxième n’avait aucune valeur pour elle.
Nous verrons assez tôt comment ajouter des données aux tableaux existants.
Supprimer une clé du modèle de données
Si vous avez une application à page unique et que la couche de données persiste tout au long de la session, vous souhaiterez peut-être supprimer certaines variables du modèle de données de temps en temps. Il suffit de retirer la clé de dataLayer ne suffira pas :
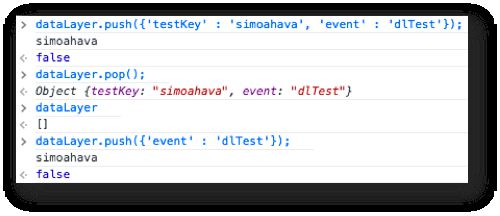
Voici ce qui se passe :
-
Je pousse ‘simoahava’ comme valeur de ‘testKey’, ceci est enregistré par la macro
-
Je supprime cet objet entier de
dataLayer -
Je le vérifie en regardant le contenu de
dataLayer -
Cependant, le modèle de données contient toujours la dernière valeur
Il s’agit en fait d’une caractéristique importante du modèle de données. Le modèle de données traite dataLayer comme un file d’attente ou un bus de messages, si vous voulez. Il fonctionne selon le principe du premier entré, premier sorti, ce qui signifie que dès que quelque chose est poussé dans dataLayeril est traité et ses valeurs sont stockées dans le modèle de données.
Cela ne fonctionnerait pas si le modèle de données devait supprimer une clé si elle est supprimée de dataLayer. Vous pouvez appuyer plusieurs fois sur la même touche avec des valeurs différentes (prenez ‘event’, par exemple). Comment le modèle de données saurait-il si vous ne faites que nettoyer des objets de la structure globale Array plutôt que de demander qu’ils soient supprimés du modèle de données ?
Une méthode de suppression dans l’interface peut être une bonne idée, mais il est tout aussi simple d’adopter l’approche générique et de pousser undefined comme valeur de la clé. Cela stockera undefined également dans le modèle de données, ce qui signifie que ce sera, à toutes fins utiles, comme si la clé n’existait plus.
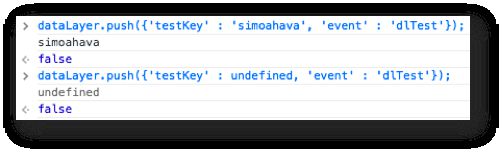
C’est aussi simple que ça.
Le tableau de commandes
C’est là que je t’ai laissé pendre tout à l’heure. Supposons que vous souhaitiez mettre à jour un tableau en ajoutant des membres à la fin ou au milieu. C’est très difficile à faire de manière générique, car vous devez d’abord récupérer le tableau à partir du modèle de données, ajouter des membres à la fin ou au milieu, puis le repousser. Et tout doit se passer au sein de la couche de données, car vous ne voulez pas que tous les autres outils et plates-formes qui utilisent la couche de données soient laissés à l’extérieur.
La façon de le faire est d’utiliser un spécial tableau de commandes. Il vous permet d’accéder aux méthodes du type de valeur que vous avez stockées dans le modèle de données.
Voici comment cela fonctionne. Je vais mettre à jour un Array [1, 3] d’abord avec deux nouveaux membres utilisant push()de sorte qu’il devienne [1, 3, 4, 5]. Ensuite, je ferai un splice(), où j’ajoute le chiffre 2 à sa juste place. Observez attentivement.

Comme vous pouvez le voir, le tableau de commandes a sa syntaxe spéciale. Tout d’abord, vous devez pousser un tableau dans la couche de données, ne pas un objet comme vous le feriez normalement.
Ensuite, le premier membre du tableau doit être une chaîne contenant la commande réelle. Tous les autres membres du tableau de commandes sont des arguments de cette commande.
Ainsi, testKey.push(4,5) devient ['testKey.push', 4, 5]et testKey.splice(1,0,2) devient ['testKey.splice', 1, 0, 2].
De cette façon, vous pouvez faire des choses intéressantes avec les valeurs stockées dans le modèle de données sans avoir à y accéder directement. L’utilisation de la couche de données garantit que d’autres outils et applications peuvent également bénéficier de vos modifications.
Méthodes personnalisées
La dernière chose que je vais vous montrer est comment effectuer des transformations personnalisées sur les valeurs stockées dans le modèle de données.
Disons que je stocke un tas de produits et de magasins dans la couche de données. Ces données sont fournies par le système backend. Il s’avère que l’un des noms de magasin est mal orthographié, et cela doit être corrigé dans le modèle de données. Effectuer une série de get et sets serait fastidieux et très inefficace. Au lieu de cela, je peux simplement pousser une fonction qui fait tout cela dans une simple boucle for.
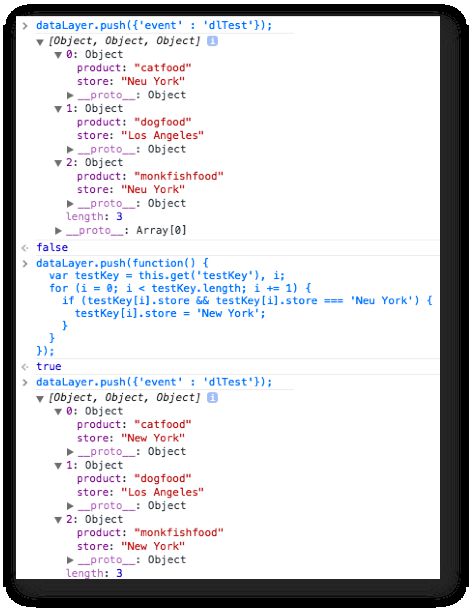
Lorsque vous poussez une fonction dans la couche de données, this sera l’interface du modèle de données sur la page. Il expose deux méthodes : get(key) et set(key, value).
Tout d’abord, j’utilise get() pour récupérer la valeur de 'testKey'. Ensuite, je fais une boucle for qui passe sur chaque membre du 'testKey' Array, recherche de la faute de frappe. Si une faute de frappe est trouvée, elle est corrigée sur-le-champ. Parce que je traite avec des objets, vous n’avez rien à remettre dans le modèle de données, puisque vous avez en fait copié une référence d’objet, pas l’objet lui-même.
Ne vous inquiétez pas de cet objet mumbo-jumbo. La clé ici est que j’ai effectué une transformation sur les données dans le modèle de données en utilisant la couche de données. De cette façon, d’autres fournisseurs et outils peuvent également bénéficier du changement. J’aurais tout aussi bien pu accéder directement à la méthode publique de l’interface, mais ce ne serait pas la manière générique de faire les choses.
Résumé
Cela a été un article compliqué, je sais, mais voici les choses que vous auriez dû apprendre.
-
La couche de données sur la page et le modèle de données utilisé par le gestionnaire de balises ne sont pas la même chose
-
La couche de données est générique, indépendante des outils et accessible à toutes les applications pouvant accéder à l’espace de noms global.
-
Le modèle de données est interne au gestionnaire de balises, il est abstrait (pas de tableaux ici) et il a une interface publique avec seulement deux méthodes
-
Certaines valeurs (tableaux, objets simples) se comportent de manière erratique lorsque vous essayez de les mettre à jour avec un push régulier
-
Vous devez toujours effectuer tous les ajouts, suppressions et transformations en utilisant la couche de données, et non en accédant directement à l’interface du modèle de données.
Si vous voulez en savoir un peu plus, jetez un œil à la spécification Data Layer Helper dans GitHub, écrite par Brian Kuhn de GTM. C’est là que la plupart des leçons ici ont été prises.
Il est si important de comprendre les subtilités de la couche de données et du modèle de données. L’un est (ou devrait être) indépendant de l’outil, l’autre est une fonctionnalité propriétaire de l’outil. L’un peut être standardisé pour servir plusieurs fournisseurs et plates-formes, l’autre doit répondre aux particularités de chaque outil séparément.
Ma présentation “Google Tag Manager For Nerds” de MeasureCamp V




