
Voici un cas d’utilisation intéressant et hacky pour vous. Il s’agit de découvrir rebond métriques pour les visites qui proviennent des résultats de recherche organiques de Google. En particulier, la métrique qui nous intéresse est la durée pendant laquelle l’utilisateur habité sur la page de destination après être arrivé de la recherche organique Google ET renvoyé à la page de résultats du moteur de recherche (SERP) à l’aide du bouton de retour du navigateur.
L’inspiration pour cet article est venue d’une question du public lors de la meilleure conférence Internet en Lituanie, à laquelle j’ai récemment assisté en tant que conférencier. Ils craignaient que Google utilise le taux de rebond comme signal de classement de recherche, et j’étais assez convaincu que ce n’était tout simplement pas possible, car toutes les métriques GA “natives” sont vraiment faciles à manipuler. Cependant, le Dr Pete de Moz a écrit sur temps de séjour en 2012, et cela a beaucoup de sens. Google devrait être très intéressé combien de temps le visiteur reste en dehors du SERP lorsqu’il suit un lien. Si les utilisateurs ont tendance à revenir immédiatement sur le SERP, il est fort probable que le résultat ne soit pas pertinent pour eux.
Donc, inspiré par cette question, je voulais voir si je pouvais obtenir des mesures sur la durée pendant laquelle les gens restent sur ces pages de destination avant de revenir au SERP. J’ai eu mes résultats, mais ce n’est certainement pas un problème facile à résoudre. Comme d’habitude, nous utilisons une combinaison de Google Tag Manager et de Google Analytics pour effectuer l’opération.
(MISE À JOUR 17 avril 2016 J’ai mis à jour cet article, car j’ai dû apporter quelques modifications au code. Il est légèrement plus robuste maintenant, et il se prête mieux, par exemple, aux métriques personnalisées, si vous préférez les utiliser au lieu de User Timings.)
Le résultat est une liste de temps d’utilisation, où chaque page de destination peut être examinée par rapport au temps que les utilisateurs y ont passé avant de cliquer sur le bouton de retour du navigateur.
Le mystère de l’histoire
La difficulté est que lorsque l’utilisateur clique sur le bouton de retour du navigateur, nous ne savons pas où l’utilisateur est redirigé. C’est la sécurité du navigateur pour vous. Il serait très douteux que le site Web ait accès à l’historique du navigateur Web. C’est logique, non ?
Une autre difficulté est le bouton de retour du navigateur. Cela ne fait pas partie du modèle d’objet du navigateur, nous ne pouvons donc pas mesurer les clics dessus. Au lieu de cela, nous pouvons déduire un clic sur le bouton de retour de la façon dont les gens naviguent avec les hachages d’URL ! Lorsqu’un changement de hachage est enregistré, nous pouvons en déduire que cela était dû au retour du navigateur si nous implémentons un petit hack, où le hachage est unique à la recherche Google organique.
Vous voyez, en créant une nouvelle entrée d’historique du navigateur pour les personnes qui arrivent à partir de la recherche organique de Google, le clic sur le bouton de retour ne les amène pas au SERP, mais plutôt à la page de destination d’origine qui existait avant nous avons redirigé l’utilisateur vers le nouvel état de l’historique. En utilisant cela comme indicateur, nous pouvons extrapoler que le changement de hachage s’est produit en raison d’un clic sur le bouton de retour du navigateur (ou le retour arrière).
Le processus
Le processus est le suivant :
-
Si l’utilisateur arrive sur le site via une recherche Google organique, créez un nouveau entrée de l’historique du navigateur avec le hachage #gref
-
Plus tard, si un changement de hachage est enregistré, et l’utilisateur est toujours sur la page de destination, et le changement de hachage est de #gref à une chaîne vide, déclenchez un événement de synchronisation Google Analytics, après quoi invoquez par programmation l’événement “Retour” dans l’historique du navigateur
Ça a l’air simple (en fait, ça n’a pas l’air simple du tout), mais c’est vraiment très piraté. Vous voyez, nous sommes manipulation de l’historique du navigateur en créant une nouvelle entrée fictive appelée #gref. Ensuite, lorsque l’utilisateur clique sur le navigateur, au lieu de le ramener à la recherche Google, il le ramène en fait à l’état précédent, qui est l’URL sans pour autant le #gref.
C’est ainsi que nous savons à la fois que l’utilisateur a cliqué sur le navigateur ET qu’il essayait de revenir au SERP. Tout ce que nous avons à faire est d’envoyer le hit de synchronisation de Google Analytics, puis de déplacer manuellement l’utilisateur vers l’entrée précédente de l’historique (c’est-à-dire le SERP).
Pourquoi c’est hacké ? Eh bien, vous manipulez l’historique du navigateur, pour commencer. Vous créez un état personnalisé et vous obligez l’utilisateur à adopter cet état s’il accède à la recherche organique. Ensuite, vous interceptez un événement de retour de navigateur légitime et, au lieu de laisser l’utilisateur quitter directement le site, vous l’obligez à envoyer d’abord le hit de synchronisation GA, avant de le renvoyer manuellement au SERP.
Ouf! Beaucoup de choses qui peuvent mal tourner. Heureusement, le JavaScript est solide et beau, mais n’oubliez pas de tester à fond !
Attendez, permettez-moi de répéter que: tester à fond. De plus, si vous utilisez un site Web d’une seule page, je peux presque vous promettre que cela ne fonctionnera pas immédiatement.
La balise HTML personnalisée
Au cœur de cette solution se trouve une seule balise HTML personnalisée. Il est déclenché par deux événements différents, sur lesquels nous reviendrons bientôt.
Tout d’abord, voici le code :
<script> (function() { var s = document.location.search; var h = document.location.hash; var e = {{Event}}; var n = {{New History Fragment}}; var o = {{Old History Fragment}}; // Only run if the History API is supported if (window.history) { // Create a new history state if the user lands from Google's SERP if (e === 'gtm.js' && document.referrer.indexOf('www.google.') > -1 && s.indexOf('gclid') === -1 && s.indexOf('utm_') === -1 && h !== '#gref') { window.oldFragment = false; window.history.pushState(null,null,'#gref'); } else if (e === 'gtm.js') { window.oldFragment = true; } // When the user tries to return to the SERP using browser back, fire the // Google Analytics timing event, and after it's dispatched, manually // navigate to the previous history entry, i.e. the SERP if (e === 'gtm.historyChange' && n === '' && o === 'gref') { var time = new Date().getTime() - {{DLV - gtm.start}}; if (!window.oldFragment) { dataLayer.push({ 'event' : 'returnToSerp', 'timeToSerp' : time, 'eventCallback' : function() { window.history.go(-1); } }); } else { window.history.go(-1); } } } })(); </script> Parcourons rapidement ce code. Tout d’abord, le bloc entier est enfermé dans une expression de fonction immédiatement invoquée (IIFE) (function() {...})();, qui protège l’espace de noms global. De plus, l’ensemble de la solution ne fonctionne que si le navigateur de l’utilisateur prend en charge l’API History : if (window.history) {...}.
Le premier bloc de code important est celui-ci :
if (e === 'gtm.js' && document.referrer.indexOf('www.google.') > -1 && s.indexOf('gclid') === -1 && s.indexOf('utm_') === -1 && h !== '#gref') { window.oldFragment = false; window.history.pushState(null,null,'#gref'); } Ce code vérifie les éléments suivants :
-
La balise a-t-elle été déclenchée en raison du déclencheur d’affichage de page (c’est-à-dire un chargement de page) ?
-
L’utilisateur a-t-il atterri à partir d’un site Google (
referrercontient www.google.) ? -
Si c’est le cas, assurez-vous qu’il ne s’agit pas d’une annonce AdWords (vérifiez que l’URL n’a pas ?gclid) ou une campagne personnalisée.
-
Assurez-vous également que l’URL ne contient pas déjà #gref, ce qui impliquerait que l’utilisateur a suivi un lien avec ce hachage ou que l’utilisateur avait déjà une entrée d’historique avec #gref, ce qui signifie qu’il a navigué ailleurs à l’intérieur ou à l’extérieur du site après atterrir dessus en premier lieu depuis le SERP.
Si ces vérifications réussissent, une nouvelle variable globale oldFragment est initialisé avec la valeur false. Cela signifie simplement qu’il s’agit d’un tout nouvel atterrissage sur le site via la recherche organique de Google, et nous vérifions cela lorsque nous poussons la charge utile vers dataLayer. Nous voulons uniquement envoyer le hit Timing pour les rebonds de la page de destination.
Enfin, un nouvel état d’historique du navigateur est créé, où l’URL est ajoutée avec #gref pour montrer que l’utilisateur a atterri à partir d’une recherche Google organique.
Le bloc de code suivant est :
else if (e === 'gtm.js') { window.oldFragment = true; } Ici, nous vérifions si l’événement est à nouveau un chargement de page, mais l’URL a déjà #gref. Dans ce cas, nous définissons la variable globale sur true, puisque évidemment cette entrée n’est pas un débarquement direct de la SERP mais autre chose. De cette façon, nous empêcherons le hit Timing de se produire, car nous ne voulons mesurer que les véritables rebonds de la page de destination.
Le bloc de code final est :
if (e === 'gtm.historyChange' && n === '' && o === 'gref') { var time = new Date().getTime() - {{DLV - gtm.start}}; if (!window.oldFragment) { dataLayer.push({ 'event' : 'returnToSerp', 'timeToSerp' : time, 'eventCallback' : function() { window.history.go(-1); } }); } else { window.history.go(-1); } } Encore une fois, il y a une liste de contrôle des choses:
-
L’événement est-il un événement de l’historique du navigateur ?
-
Est le vieux hachage #gref et le nouveau hachage une chaîne vide?
Si toutes ces vérifications réussissent, cela signifie que l’utilisateur a tenté de revenir dans l’historique du navigateur à la SERP. En raison de notre état d’historique imposé manuellement, ils sont en fait transférés vers le #gref-moins de page de destination.
Ensuite, nous vérifions le temps d’attente sur la page, en utilisant la différence entre l’heure actuelle et l’heure à laquelle l’extrait de conteneur GTM a été chargé pour la première fois. Il s’agit d’une description raisonnable du temps de séjour, mais vous pouvez utiliser autre chose pour le temps de démarrage si vous le souhaitez.
Enfin, nous vérifions si oldFragment est faux, ce qui signifie que nous sommes toujours sur la page de destination. Si c’est le cas, la charge utile est poussée dans dataLayer. La clé ‘eventCallback’ a le retour réel à la commande SERP, et elle ne sera exécutée qu’après toutes les balises qui utilisent le returnToSerp événement ont tiré.
Hacky-dy-hack-hack ! Je l’aime!
Toutes les autres choses dont vous aurez besoin
Voici une liste des actifs que vous devez créer pour que cela fonctionne. N’hésitez pas à improviser, si vous le souhaitez !
1. Variables intégrées
Tout d’abord, assurez-vous que les variables intégrées suivantes sont cochées dans les paramètres de variables de votre conteneur.

Donc, c’est L’URL de la page, Événement, Source de l’historique, Nouveau / ancien fragment d’histoire.
2. Les déclencheurs de la balise HTML personnalisée
La balise HTML personnalisée s’exécute sur deux déclencheurs.
Le premier est la valeur par défaut Toutes les pages Déclencheur.
Le deuxième est un Modification de l’historique Déclencheur qui ressemble à ceci :
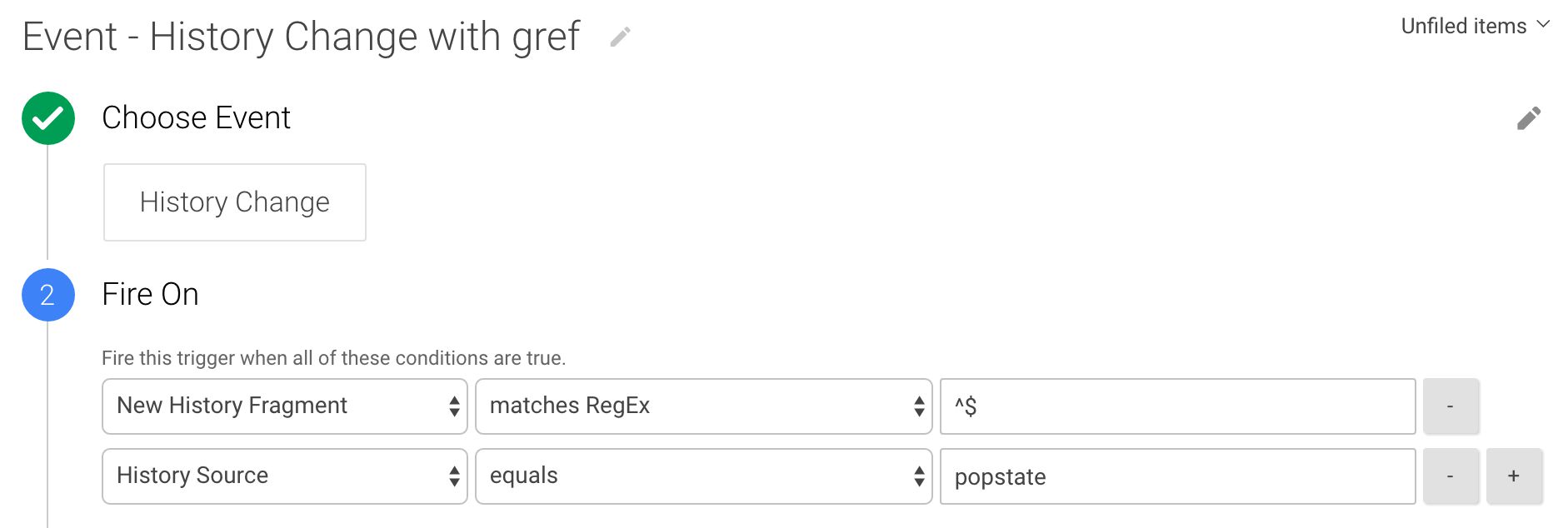
Ce déclencheur ne se lance que lorsqu’un événement d’historique du navigateur est détecté, ce qui est également un popstateet le nouveau fragment d’historique est vide.
3. Les Variables
Créez les variables de couche de données suivantes :
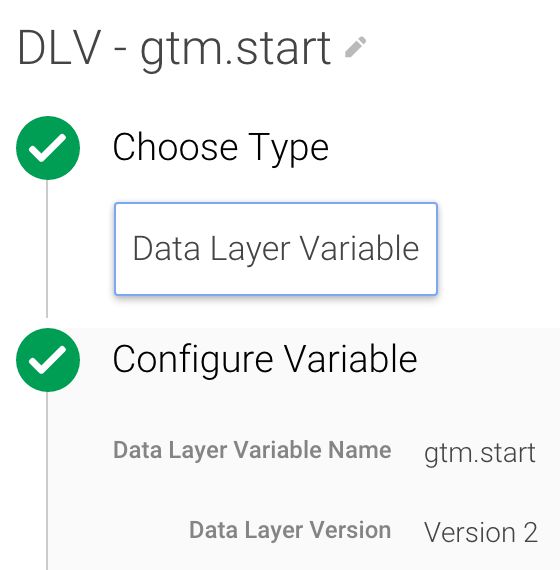
Celui-ci stocke l’heure à laquelle l’extrait de conteneur GTM a été exécuté.
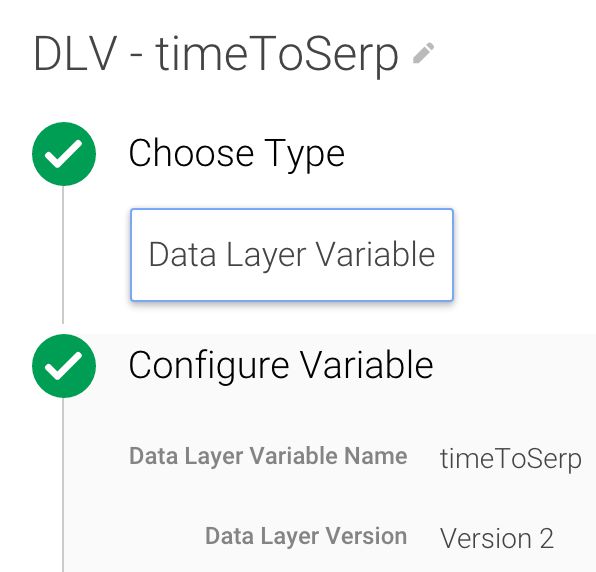
C’est là que le temps passé sur la page de destination est stocké.
4. Le déclencheur de l’étiquette de synchronisation
Le déclencheur que vous attacherez à la balise de synchronisation (créée ensuite) ressemble à ceci :
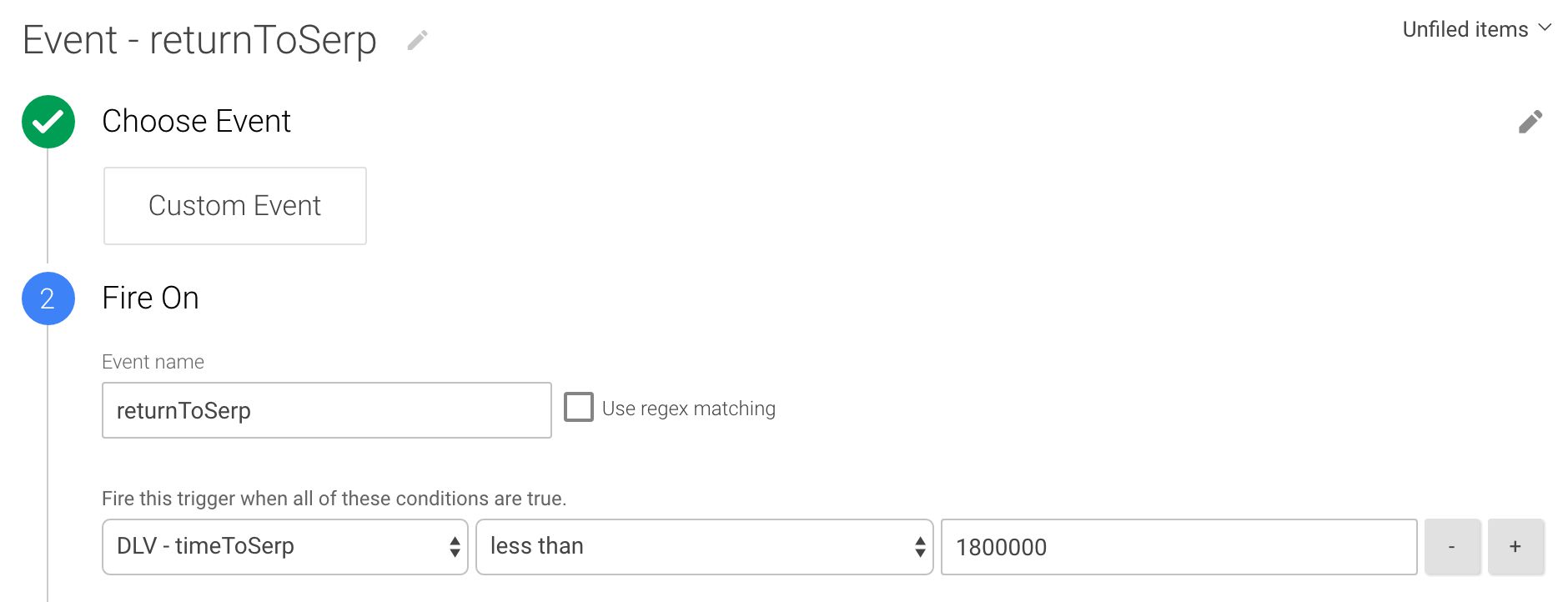
Ce déclencheur se déclenche lorsque le returnToSerp dataLayer événement est envoyé via la balise HTML personnalisée. Il vérifie également que le temps de séjour poussé dans dataLayer est inférieur à 30 minutes. De cette façon, une nouvelle session ne sera pas démarrée avec l’événement, si le visiteur reste sur la page pendant une durée exceptionnellement longue.
5. L’étiquette de synchronisation
Et voici la balise de synchronisation Universal Analytics dont vous aurez besoin :

Nous envoyons Rebond SERP en tant que catégorie de chronométrage, le plein L’URL de la page comme variable temporelle, et la temps passé sur la page de destination comme valeur. Comme mentionné ci-dessus, cette balise est déclenchée par le déclencheur que vous avez créé à l’étape (4) ci-dessus.
Affichage des résultats
Une fois cela mis en œuvre, vous trouverez les résultats sous Contenu du site > Vitesse du site > Timings utilisateur sous la catégorie Timing étiquetée Rebond SERP.
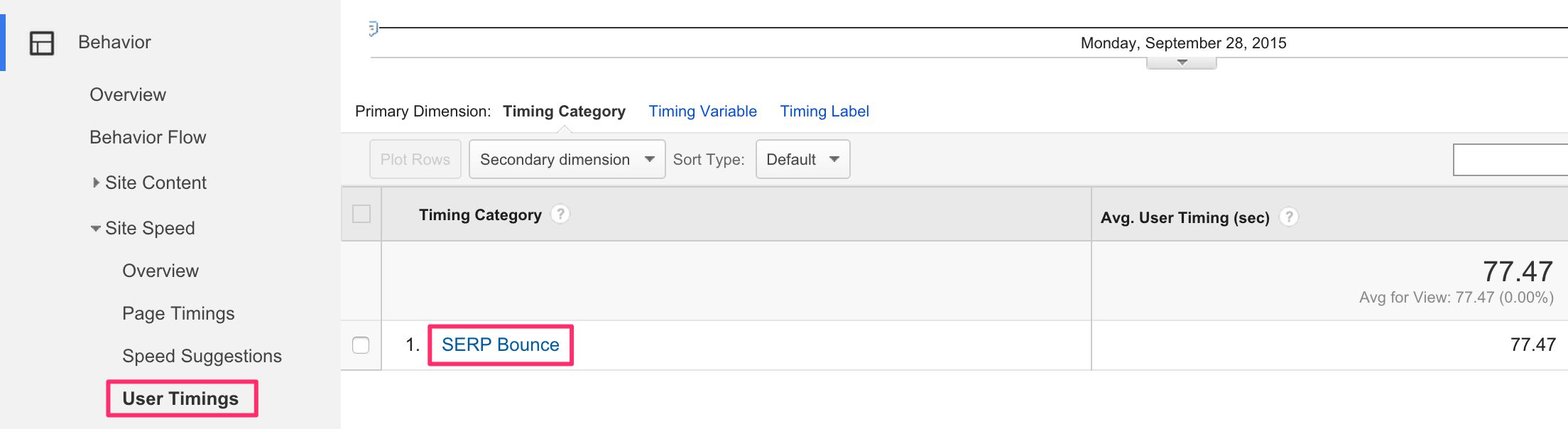
Pour explorer les données, il est utile d’afficher la variable de synchronisation comme dimension principale, car c’est celle où se trouvent les pages de destination. Essayez de trouver des pages de destination avec un temps de séjour moyen anormalement petit :

Ces pages ont un temps d’attente très court par rapport à la moyenne du site. Assurez-vous simplement que le échantillon de synchronisation est suffisamment grand pour que vous en tiriez des conclusions. Pages avec un temps de séjour anormalement court de la SERP POURRAIT indiquer une mauvaise expérience ou un manque de contenu pertinent.
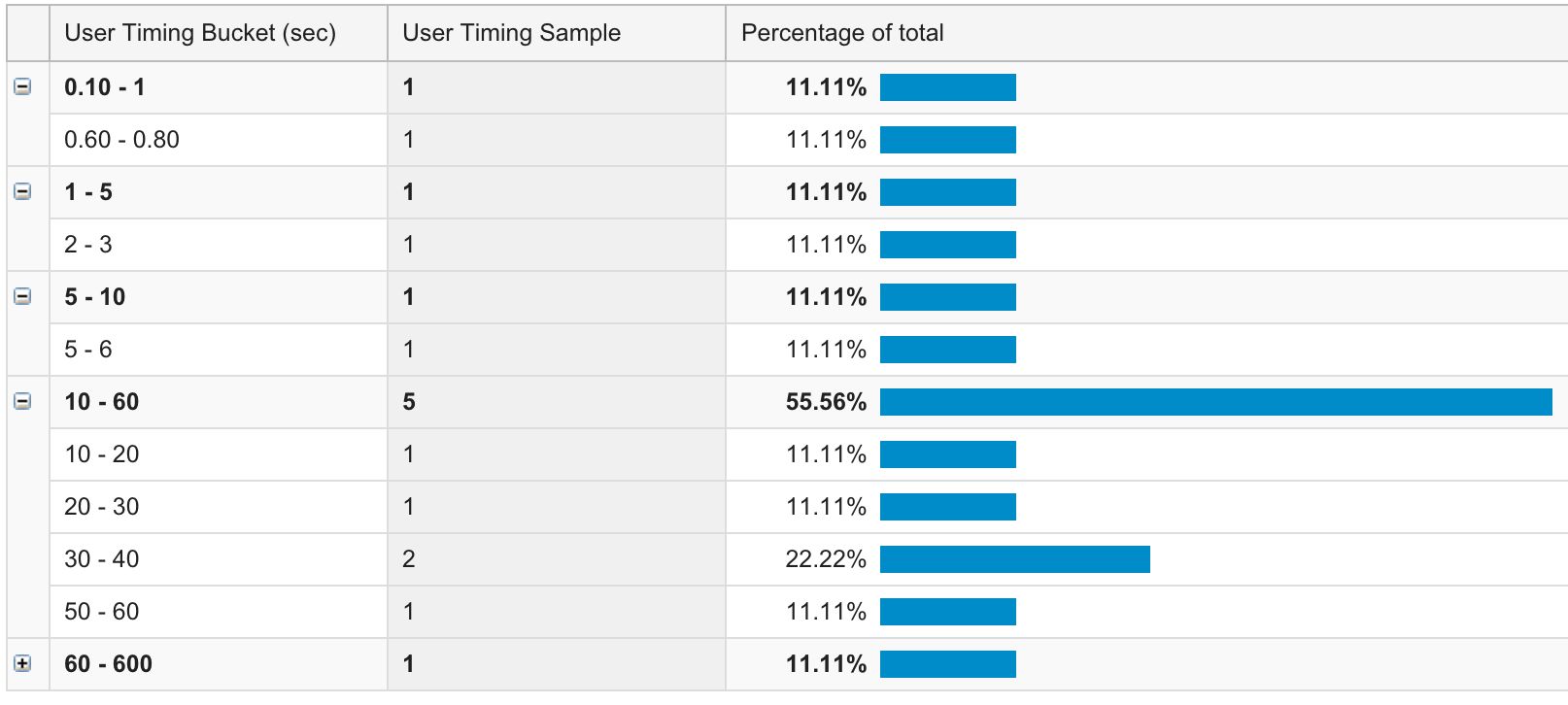
Également Distribution view est utile si vous souhaitez explorer les performances de chaque page :
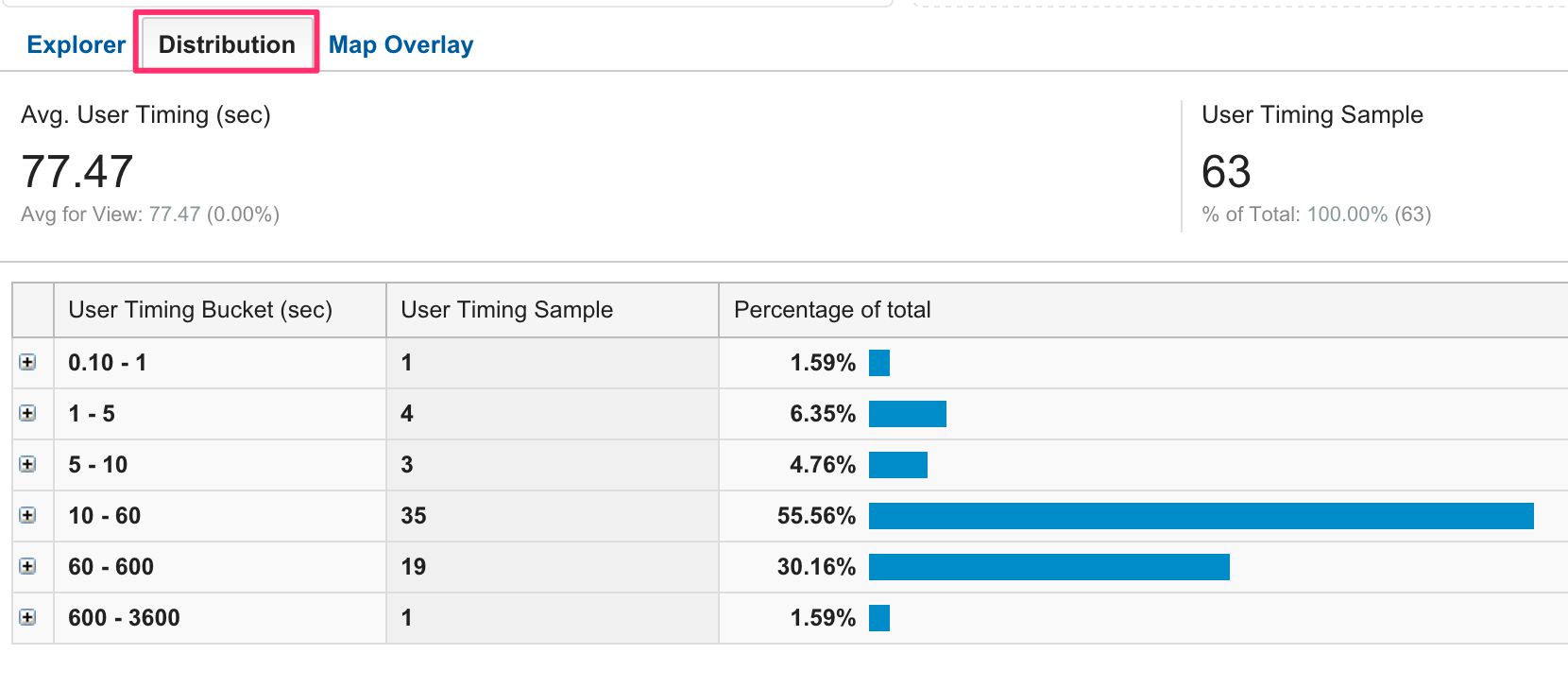
Ce rapport vous permet d’afficher les intervalles de temps. Comme vous pouvez le voir, il y a quelques anomalies ici, même si l’échantillon est assez petit.
Résumé
J’espère que je vous ai convaincu maintenant qu’il s’agit d’une solution très hacky. N’oubliez pas de tester soigneusement. Je peux également vous promettre que vous rencontrerez des problèmes si vous essayez de l’implémenter sur une application d’une seule page (par exemple, un site AJAX), qui s’appuie sur l’API d’historique du navigateur pour la navigation.
Néanmoins, c’est un moyen intéressant de découvrir les problèmes potentiels avec vos pages de destination. Il serait intéressant d’aligner ces données avec les données de mots-clés, mais c’est à vous de résoudre, car ces données sont difficiles à obtenir de nos jours, et les horaires des utilisateurs ne s’alignent pas bien avec les dimensions d’acquisition comme les mots-clés.




