
Si vous utilisez Google Analytics, Google Tag Manager ou toute plateforme de collecte ou d’analyse de données basée sur JavaScript, vous êtes-vous déjà demandé comment ils fonctionnent réellement ? Je veux dire, vous vous souciez évidemment de l’obtention des données, mais prenez-vous les machinations de ces outils pour acquises ?
C’est quelque chose auquel je pense depuis longtemps, car je ne suis pas sûr que beaucoup de ceux qui travaillent avec ces plates-formes comprennent réellement comment le navigateur et la page Web interagissent.
Cela n’a aucun sens. Et ça me fait un peu peur.
Étant donné que le paradigme prédominant de l’analyse Web tourne aujourd’hui autour de JavaScript, il est important d’avoir une idée des maillons faibles de cette technologie. De plus, avant même que JavaScript n’entre en jeu, vous devez observer certains aspects du processus de chargement de la page pour obtenir des données de meilleure qualité.
Heureusement, même la compréhension la plus basique de ceux-ci conduit à l’élucidation : Non, les outils ne couvrent pas 100 % des visites sur votre site, non, les « pages vues », les « sessions » et les « utilisateurs » ne doivent pas être pris au pied de la lettre, et non, ce n’est généralement pas Google Tag Manager ou Google Analytics qui est en cause lorsque le suivi sur votre site échoue. Vous trouverez le vrai coupable en ouvrant la console JavaScript sur votre site Web chéri, mais n’oubliez pas de fermer cette faille dimensionnelle aux fosses inférieures de l’enfer de tous les enfers une fois que vous avez terminé, de peur que certains des démons ne deviennent par.

Le cœur de cet article se résume à une simple déclaration :
La seule façon d’évaluer la qualité des données que vous utilisez est de comprendre comment elles ont été collectées.
Gardant cela à l’esprit, je souhaite examiner la séquence de chargement de la page dans le navigateur de l’utilisateur et les implications des différentes parties du processus de chargement sur le suivi Google Analytics.
La séquence d’événements dans le chargement de la page

Ce court essai (ou longue diatribe, comme vous voulez le voir) est divisé en plusieurs sections. Chaque section représente une étape du processus complexe de ce qui se passe dans le navigateur de l’utilisateur lorsqu’il visite votre site Web. Chaque partie de ce processus a des implications sur la façon dont vous pouvez et devez suivre les interactions de cet utilisateur avec votre contenu.
-
La demande – Que se passe-t-il lorsqu’un utilisateur saisit une adresse dans la barre d’adresse du navigateur et quels sont les points de pression pour le suivi Web.
-
Le rendu – Comment le navigateur transforme le code source en un document vivant.
-
The Race – Comment fonctionne le JavaScript asynchrone, quelles sont les conditions de concurrence et ce à quoi vous devez faire attention.
-
L’interaction – Une fois la page chargée, comment les interactions des utilisateurs sont-elles mesurées et quels sont les plus grands pièges ici.
Comme toujours, je termine par un résumé.

Tout commence par la demande.
Lorsqu’un utilisateur tape l’adresse de votre site Web dans la barre d’adresse du navigateur, le résultat souhaité est généralement qu’il voit une page Web. Pour que cela se produise, le navigateur utilise le protocole HTTP pour envoyer une requête à la machine qui se cache derrière l’adresse.
S’il y a un serveur Web à ce point de terminaison, si ce point de terminaison a mappé l’adresse demandée à une ressource et si la demande est valide (aucune authentification supplémentaire n’est requise, les pare-feu ne bloquent pas la demande, aucune politique de sécurité n’est violée, etc. ), le serveur Web envoie une réponse “OK”, le plus souvent avec un code d’état 200 et le document qui a été mappé à l’adresse dans le corps de la réponse.
Ce document est généralement un fichier de modèle HTML, c’est-à-dire le code source de la page, et le travail du navigateur consiste à transformer ce document en une page Web dynamique.
Je veux dire, évidemment, c’est un processus beaucoup plus complexe et complexe que cela, mais l’interaction clé ici est ce qui se passe lorsque le serveur Web reçoit la demande.
Pour une collecte réussie des données vers Google Analytics, vous devez être conscient de certaines choses ici.
1) 404 – Ressource introuvable
S’il n’y a pas de ressource mappée à l’adresse demandée par l’utilisateur, cela signifie que le serveur Web doit répondre avec une erreur “ressource introuvable”. Maintenant, à ce stade, votre serveur Web doit être configuré de sorte que s’il n’y a pas de ressource à envoyer à l’utilisateur, un modèle “Page introuvable” soit servi à la place.
Vous devriez avoir GA en cours d’exécution sur cette page avec une balise qui suit les pages vues. Le suivi des pages 404 est un merveilleux ajout à l’ensemble d’outils de tout webmaster-slash-analyste avisé.
Si vous n’avez pas configuré de modèle, l’utilisateur peut voir la page d’erreur par défaut servie par votre serveur Web (ils sont généralement assez horribles), ou, à défaut, le navigateur préparera un message d’erreur à la place (encore plus horrible ). La clé ici est que si vous n’avez pas de modèle personnalisé avec le code de suivi GA, vous ne pourrez pas suivre ces appels dans Google Analytics. Par exemple, mes outils GTM servent la page par défaut suivante, inutile et impossible à suivre si aucune ressource n’est trouvée :

C’est une mauvaise pratique. Utilisez plutôt un modèle personnalisé.
Consultez le post Bounteous si vous voulez voir un excellent moyen de suivre les erreurs 404 dans GA et GTM !
2) Redirections
Si vous avez configuré une redirection côté serveur, vous devez vous rappeler conserver les paramètres de la chaîne de requête dans la redirection ! Si vous les supprimez dans la redirection, vous risquez de perdre d’importantes informations de suivi de campagne.
C’est essentiel pour préserver la qualité des données !
3) Applications d’une seule page
Si votre site Web est essentiellement une application d’une seule page, où au lieu de la requête HTTP GET attendue, le navigateur de l’utilisateur envoie des appels POST, les règles du suivi de page traditionnel changent un peu.
Vous ne pouvez plus faire confiance à la réinitialisation qui se produit à chaque chargement de page, car il n’y a en fait aucun chargement de page après le premier. Au lieu de cela, vous allez devoir trouver une nouvelle terminologie pour suivre vos visiteurs. Pour certains, il s’agit du suivi du défilement, via des événements ou des pages vues virtuelles, et pour certains, il s’agit du suivi des interactions de l’utilisateur avec la page, telles que le clic sur des onglets ou des boutons d’appel à l’action, et pour certains, il invoque l’écouteur d’historique de GTM, qui réagit aux changements de état du navigateur.
Si vous utilisez Google Tag Manager, un aspect important de ces applications d’une seule page est que le dataLayer l’objet n’est pas réinitialisé comme il l’est avec les actualisations de page. En effet, dans un contexte Web, la page Web minutieusement rendue avec toutes ses variables, objets, éléments, textes, liens, images et autres encombrements est recréée à chaque actualisation de la page. En d’autres termes, les objets d’une page donnée ne persistent pas sur les autres pages. Avec une application d’une seule page, il n’y a pas d’actualisation de page, donc pas de purge. La couche de données est active pendant tout le temps que l’utilisateur reste sur la page, ce qui signifie qu’il est plus que possible que tout ce que vous stockez dans dataLayer et envoyer à GA peuvent également être envoyés avec les appels suivants.
Avec les applications d’une seule page, vous devez donc être conscient de l’état de dataLayer à tout moment, et si nécessaire, vous devez émuler un rafraîchissement de page en supprimant les clés que vous ne souhaitez pas conserver :
dataLayer.push({ 'key_to_be_deleted' : undefined }); 4) Ne soyez pas idiot… idiosyncratique
Enfin, un aspect important de l’interaction avec le serveur Web est que de nombreuses plates-formes d’analyse attendent un comportement standard de votre serveur. Alors ne préparez pas vos propres réponses personnalisées si le simple « 200 OK » suffit. Si vous ne fournissez pas de réponses standard, il est possible que les rappels ne soient pas exécutés, que les appels ne soient pas envoyés et que des données précieuses soient à nouveau perdues.
La clé à retenir ici est la suivante :
Adhérez aux meilleures pratiques en matière de gestion des modèles et de réponses du serveur – votre outil d’analyse vous remerciera avec de bonnes données.

Lorsque le navigateur reçoit le code source, il fait quelque chose d’inexcusable. Cela donne une pause au site Web. Vous voyez, l’une des raisons pour lesquelles JavaScript est vilipendé et que les guerres de navigateurs font rage est que les erreurs sont passées sous silence. Votre site peut avoir le code source le plus horrible, mais selon le navigateur, il se transforme en un document Web dynamique, étonnant et bien conçu.
C’est un peu comme ce que fait Auto-Tune aux chanteurs sans talent. L’industrie de la musique utilise Auto-Tune pour transformer les décrocheurs d’Idol en pop stars. De la même manière, le navigateur Web transforme un hideux anti-code en une page Web sans dire franchement au développeur qu’il a fait un mauvais travail.
Maintenant, nous pouvons affirmer que Auto-Tune est une bonne chose, et nous pouvons affirmer que c’est formidable que le navigateur vous aide comme ça. Mais avoir une machine qui corrige votre chant n’est pas une excuse pour arrêter d’essayer d’atteindre naturellement la hauteur correcte, et avoir un navigateur qui corrige vos problèmes de code source n’est pas une raison pour ne pas viser un bon balisage.
Pour l’analyse, ce comportement du navigateur a des implications.
Parce que chaque navigateur veut être un peu meilleur que le suivant, ils ont leurs propres façons d’analyser le code source. Parfois, ces idiosyncrasies sont suffisamment subtiles pour ne pas faire de dégâts, mais parfois elles se transforment en problèmes de compatibilité à part entière, en polyfills et en développeurs mécontents. Au cœur de cette tragédie se trouve l’analyste, qui voulait seulement savoir combien de personnes laissaient un champ de formulaire spécifique vide lors de la soumission du formulaire de contact.
// Classic example of browser compatibility checking if (document.addEventListener) { // For real browsers document.addEventListener('click', handleClick); } else { // For IE8 and earlier document.attachEvent('onclick', handleClick); } Pour lutter contre ces problèmes dans le processus de rendu, il est souvent judicieux d’adopter un framework. Si vous suivez la « voie traditionnelle », jQuery est quelque chose que vous voudrez peut-être jeter un œil. Si vous utilisez Google Tag Manager, eh bien, vous utilisez déjà un framework JavaScript. En tirant parti des fonctionnalités intégrées de GTM, telles que le suivi automatique des événements et les modèles de balises, vous externalisez les problèmes inter-navigateurs vers Google Tag Manager. C’est le travail du framework de veiller à ce que toutes les fonctionnalités que vous souhaitez utiliser fonctionnent sur la grande variété de navigateurs et d’appareils.
Dans certains cas, même le navigateur le plus intelligent ne vous aidera pas. Ceux-ci sont appelés points de défaillance uniques, car ils perturbent essentiellement le contexte d’exécution actuel lorsqu’une erreur se produit. Si vous exécutez JavaScript, tel que l’extrait de code de suivi Universal Analytics dans votre modèle de page, une seule erreur de syntaxe rompra le contexte de script actuel et le code échouera. Encore une fois, votre navigateur essaie probablement d’être utile et ne déclenche aucune alarme si cela se produit, vous devrez donc effectuer un débogage. Faites de la console JavaScript de votre navigateur votre nouveau meilleur ami. Utilisez-le religieusement pour le débogage.

C’est dommage si l’ensemble de votre plan de suivi pour un site Web échoue à cause d’une citation mal saisie ou d’un point-virgule manquant. Aussi, n’oubliez pas de faire attention aux guillemets formatés. Si vous copiez-collez à partir d’un document où les guillemets sont formatés de manière peu orthodoxe (comme Microsoft Word), vous risquez de rencontrer des problèmes avec les compilateurs JavaScript, qui attendent des guillemets réguliers et non formatés dans le code.
Ainsi, la clé à retenir dans le processus de rendu est :
Assurez-vous que votre [markup is valid](http://validator.w3.org/), et que votre [JavaScript is flawless](http://jslint.com/). Si votre JavaScript devient trop complexe à gérer, jetez un coup d’œil à un cadre durable qui éliminera une partie des frais généraux de gestion.

JavaScript est monothread. Cela signifie qu’à un moment donné, une seule ligne de JavaScript peut être exécutée. Ainsi, JavaScript est, par nature, bloquant. Chaque ligne de JavaScript exécutée sur le modèle de page bloque le modèle jusqu’à ce que la ligne de code ait été exécutée.
Avant que le JavaScript asynchrone ne devienne la norme, nous avions recours à l’ajout de JavaScript potentiellement risqué à la fin du document, tout en bas. Cela réduisait le risque de panne de toute votre page Web si le JavaScript refusait d’être d’accord avec le navigateur. De plus, si des fichiers JS externes très volumineux étaient chargés, ces appels étaient également ajoutés à la fin de la page, car le chargement et l’exécution du fichier externe étaient successivement mis en file d’attente, ce qui signifiait qu’un blocage important de la page aurait lieu.
Eh bien, aujourd’hui, nous avons du JavaScript asynchrone. Au cœur du JavaScript asynchrone se trouvent rappels, qui sont des fonctions qui sont exécutées une fois qu’une action, généralement une requête réseau, est traitée. Ainsi, si, par exemple, votre script effectue une requête HTTP, JavaScript asynchrone lance la requête, mais revient immédiatement à la ligne de code suivante dans le modèle de page. Au fur et à mesure que la requête progresse, les rappels sont exécutés dès qu’il y a une place libre dans la file d’attente des événements. De cette façon, le code ne bloque pas le chargement de la page, car il est exécuté “en arrière-plan”, n’exécutant les rappels qu’une fois qu’ils sont invoqués par la fonction d’origine.
Un autre endroit où vous verrez des requêtes asynchrones est lors du chargement de bibliothèques JS externes. Google Analytics et Google Tag Manager sont tous deux chargés de manière asynchrone. Cela signifie que la demande de chargement du fichier JavaScript est envoyée de manière asynchrone et que lorsque le fichier est chargé et disponible, le code qu’il contient est exécuté (et lorsqu’il y a une place dans la file d’attente des événements). De cette façon, vous pouvez ajouter ces chargements de bibliothèques externes en haut de la page, en vous assurant que leur processus de chargement commence le plus tôt possible dans le chargement de la page, mais sans risquer qu’ils bloquent l’exécution de votre autre code.
L’inconvénient du JavaScript asynchrone est que nous ne pouvons pas vraiment prédire quand un script donné finira de s’exécuter. Nous saurons lorsque il se termine grâce aux rappels, mais nous ne pouvons pas identifier ce moment dans la séquence de chargement de la page au préalable.
Ce comportement conduit à ce qu’on appelle des conditions de concurrence. Les conditions de concurrence se produisent lorsque deux scripts sont chargés de manière asynchrone, et le dernier nécessite que le premier se termine en premier. Un exemple serait le suivi des événements dans GA. Vous ne voulez pas envoyer d’appel d’événement avant la fin de l’appel de page vue, car sinon vous vous retrouverez avec des sessions déformées, où la page de destination est (non définie) :

Si des conditions de concurrence sont en jeu, peu importe que le hit d’événement ait commencé son exécution après la consultation de la page. Ce qui compte, c’est que l’événement puisse se terminer en premier, car nous ne pouvons pas contrôler l’exécution asynchrone une fois qu’elle a commencé.
Pour GA et GTM, il est important que vous reconnaissiez les conditions de concurrence potentielles sur votre page. Si vous souhaitez augmenter les chances que la page vue soit envoyée avant tout accès ultérieur, par exemple, vous pouvez configurer tous les autres accès pour qu’ils attendent au moins jusqu’à ce que le DOM de la page ait été chargé. Cette mesure de sécurité ajoute généralement une petite surcharge à l’exécution de la balise qui attend DOMComplete, et cela signifie le plus souvent que la page vue a eu suffisamment de temps pour se terminer avant que d’autres hits ne soient envoyés.
S’il ne s’agit pas de données critiques pour l’entreprise, vous pouvez même utiliser l’événement de chargement de fenêtre comme crochet pour vos autres hits. La fenêtre est chargée lorsque la page et tous les scripts associés ont fini de se charger. Si votre code pousse les données vers GA après le chargement de la fenêtre, il est presque certain à 100 % que la page vue a fini de s’exécuter. Cependant, si vous avez une page lourde pleine de grandes images non mises en cache (boo !) et des tas de fichiers JS externes à charger (boo boo !), l’attente peut être trop longue pour certains visiteurs impatients. Ainsi, tous les hits qui attendent le chargement de la fenêtre peuvent ne pas être envoyés, car l’utilisateur a déjà navigué vers une autre page.
La meilleure façon de s’assurer que les scripts asynchrones se chargent en séquence, et donc d’éviter les conditions de concurrence, est d’utiliser le rappel d’un hit réussi comme déclencheur pour les hits suivants. Ainsi, dans votre page vue, vous pouvez utiliser le paramètre hitCallback pour spécifier ce qui se passe une fois que la balise a été déclenchée avec succès. Dans cette fonction de rappel, vous pouvez indiquer à vos autres balises qu’elles peuvent être déclenchées. Avec Google Tag Manager, en utilisant hitCallback avec dataLayer rend vraiment facile d’introduire un peu d’ordre dans les choses.
Comprendre les conditions de concurrence est également très important avec le commerce électronique, surtout si vous utilisez des requêtes HTTP côté client pour obtenir les données de transaction. Il est trop courant de voir une balise de transaction s’exécuter avant que les données de transaction ne soient disponibles.
Le plat à emporter de The Race est:
Cartographiez les dépendances entre vos balises, éliminez les conditions de concurrence à l’aide de rappels et exploitez autant que possible le chargement asynchrone.

Eh bien, tous ces éléments de chargement de page sont légèrement intéressants, mais ils pourraient ne pas jouer de rôle dans votre idée de ce à quoi sert l’analyse Web, même si cela devrait être le cas. Mais ce qui vous intéresse vraiment, c’est comment suivre les interactions sur le site.
Interaction est un terme chargé, car il est souvent difficile de déterminer exactement ce que nous entendons par une interaction utilisateur. Un clic est sûrement une interaction, mais le défilement est-il une interaction ? Qu’en est-il du mouvement de la souris, est-ce une interaction ? Qu’en est-il du déplacement du regard de l’utilisateur vers une autre partie du site, ce n’est sûrement pas une interaction ? Eh bien, c’est peut-être le cas.
Le fait est qu’en fonction de ce que vous souhaitez suivre, vous pourriez rencontrer de nombreux problèmes lors de la mise en œuvre du système qui collecte les données. Quelque chose d’aussi simple qu’un gestionnaire de clics peut être difficile à mettre en œuvre si vous n’êtes pas conscient des conflits possibles avec vos autres gestionnaires JavaScript.
Cette résolution de conflits couvre environ 75 % des questions les plus fréquemment posées sur Google Tag Manager. J’ai déjà beaucoup écrit à ce sujet, donc si vous voulez des détails détaillés sur le propagation d’événement problème, regarde cet article :
Pourquoi mes auditeurs GTM ne fonctionnent-ils pas ?
La clé ici est de comprendre comment fonctionne le modèle d’objet de document, en particulier en termes de délégation d’événements. Il est souvent plus économique d’ajouter un seul écouteur sur une page, puis de simplement récupérer les événements à l’aide de la délégation d’événements. Cependant, si vous avez un script en conflit sur la page, cela peut ne pas fonctionner et vous devez trouver une solution de contournement. Voici une version simplifiée du problème :
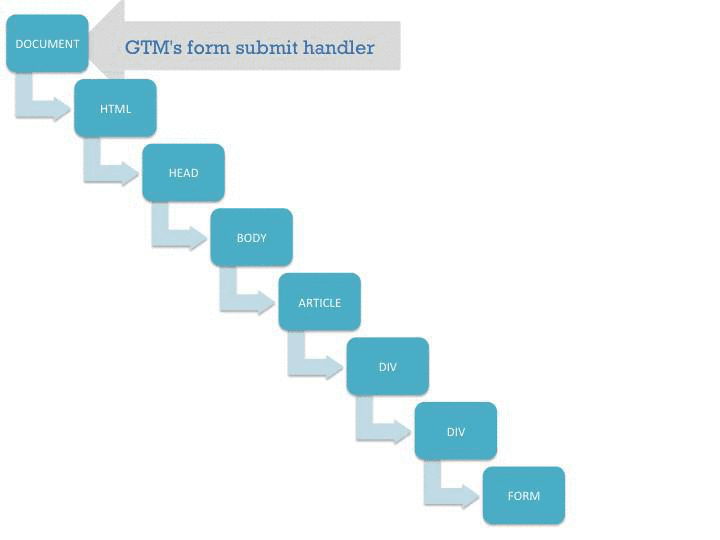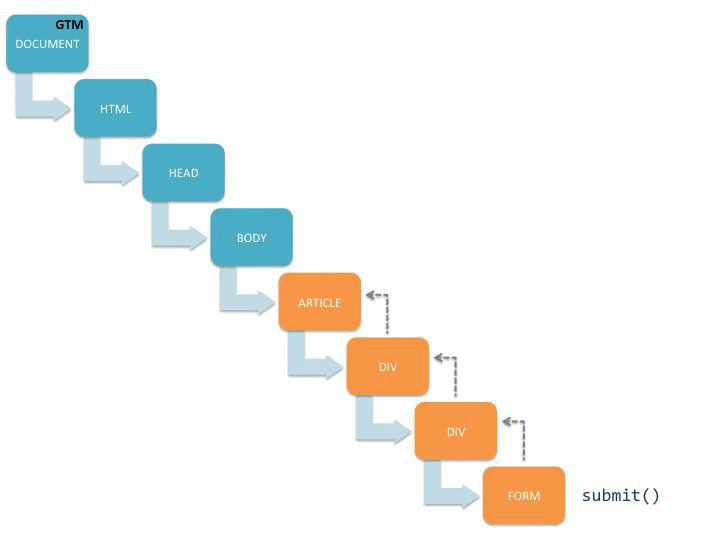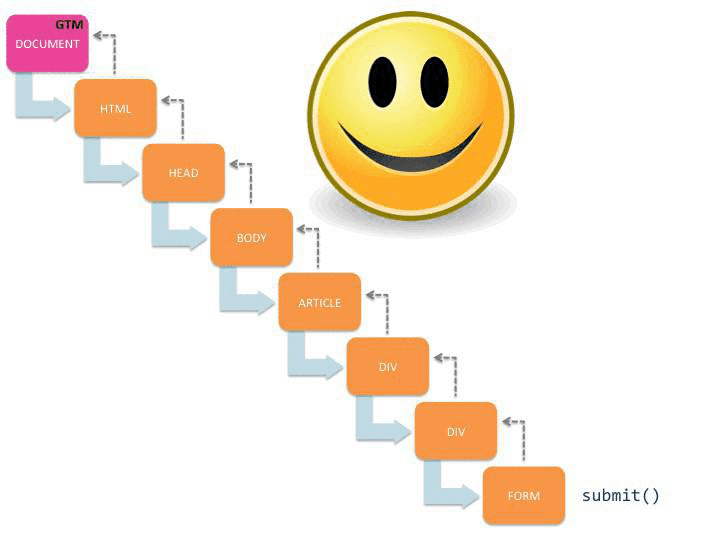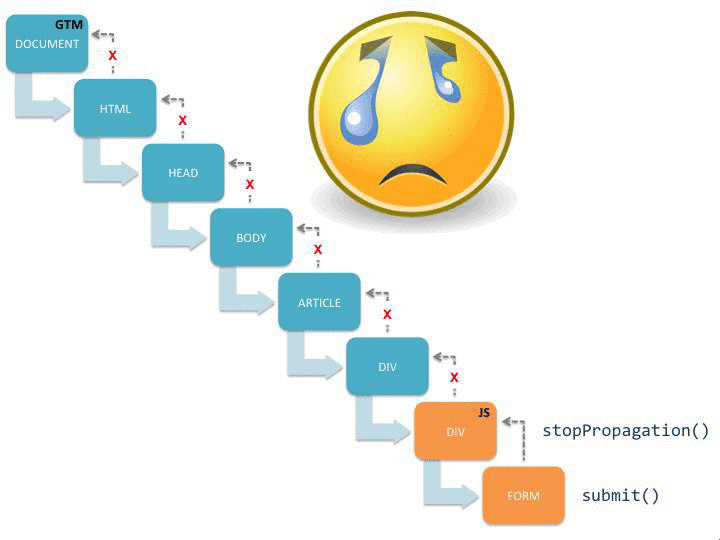
Cette visualisation montre comment le submit() commence à se propager dans l’arborescence du document, et une fois qu’il atteint les écouteurs de GTM sur le document node, le suivi automatique des événements démarre. Il vous montre également ce qui se passe s’il y a un appel intrus à stopPropagation() sur l’objet événement.
Mais c’est GTM. Lorsque vous effectuez un suivi avec GA traditionnel, vous pouvez à nouveau utiliser jQuery pour une gestion facile des événements entre navigateurs. Le fait est que plus vous exploitez différents frameworks, plus il y a de chances que les choses tournent mal.
Avec le suivi des interactions, il est si important d’établir une discussion avec vos développeurs front-end. Si vous commencez à injecter des éléments sur le site qui ne fonctionnent pas bien avec l’infrastructure de script existante, vous aurez des problèmes bien plus importants que la pollution des données. Vos formulaires peuvent ne plus fonctionner, les onglets censés modifier le contenu de manière dynamique commencent à vous rediriger vers des pages complètement différentes, les éléments clignotent de manière agaçante, etc.
Donc, la clé à retenir pour le suivi des interactions est la suivante :
Ne suivez que ce que vous pensez utile de suivre et testez toujours soigneusement les conflits
Le résumé
Je déteste juste gratter la surface dans les articles, mais nous avons déjà dépassé les 3 000 mots et si vous êtes arrivé jusqu’ici, vous méritez un immense merci.
L’analyse est globale. Il peut imprégner chaque plate-forme que vous utilisez, regroupant des informations provenant d’une grande variété de sources de données dans un emplacement centralisé. Cependant, pour que votre analyse Web fonctionne au maximum, je crois fermement qu’une compréhension du processus de chargement de la page, même à un niveau élevé, est cruciale. Cet article n’a fait qu’effleurer la surface, vous pouvez donc consulter les ressources suivantes pour élargir votre esprit :
-
La demande : comment fonctionnent les navigateurs
-
La demande : Google Analytics et les redirections 301/302
-
Le rendu : optimiser le contenu pour différents navigateurs
-
Le rendu : QuirksMode : aperçu de la compatibilité
-
La course : programmation JavaScript asynchrone
-
The Race : #GTMTips : hitCallback et eventCallback
-
L’interaction : écouteur d’événement personnalisé pour GTM
-
L’interaction : événements Google Tag Manager utilisant des attributs de données HTML5



