
Depuis sa sortie, le balisage côté serveur dans Google Tag Manager s’exécutait sur le Plate-forme Google Cloud pile, mon imagination s’est emballée.
En s’exécutant sur GCP, le potentiel d’intégration avec autre Les composants GCP sont illimités. La sortie vers Cloud Logging présente déjà des opportunités de pipeline intéressantes, mais maintenant elle s’améliore encore.
Il est enfin possible d’écrire directement dans Google BigQuery depuis un template de Client ou de tag !

Cela signifie qu’au lieu de traiter le balisage côté serveur comme un “simple” Procurationdont le but est principalement de remplacer les flux de données qui connecteraient autrement un client directement à un point de terminaison, il est désormais possible d’utiliser un conteneur de serveur comme une machine de collecte de données elle-même.
Dans cet article, je vais vous montrer comment utiliser l’API BigQuery avec un cas d’utilisation que vous connaissez peut-être déjà. Nous allons construire un Système de surveillance qui écrit les données d’exécution des balises dans une table Google BigQuery.
Ce ne sera pas la dernière fois que j’écrirai sur cette intégration – il y a un parcelle de possibilités disponibles maintenant qu’un moyen d’écrire nativement des données dans un entrepôt de données à partir du conteneur Server est devenu disponible.
Nous commencerons par un procédure pas à pas avant de plonger dans Spécifications de l’API.
Documents officiels
Vous pouvez trouver la documentation officielle du modèle d’API BigQuery en suivant ce lien :
API de balisage côté serveur : BigQuery
Exemple complet : créer un système de surveillance
Pour commencer, nous allons créer un moniteur Google Tag Manager pour vos balises côté serveur.
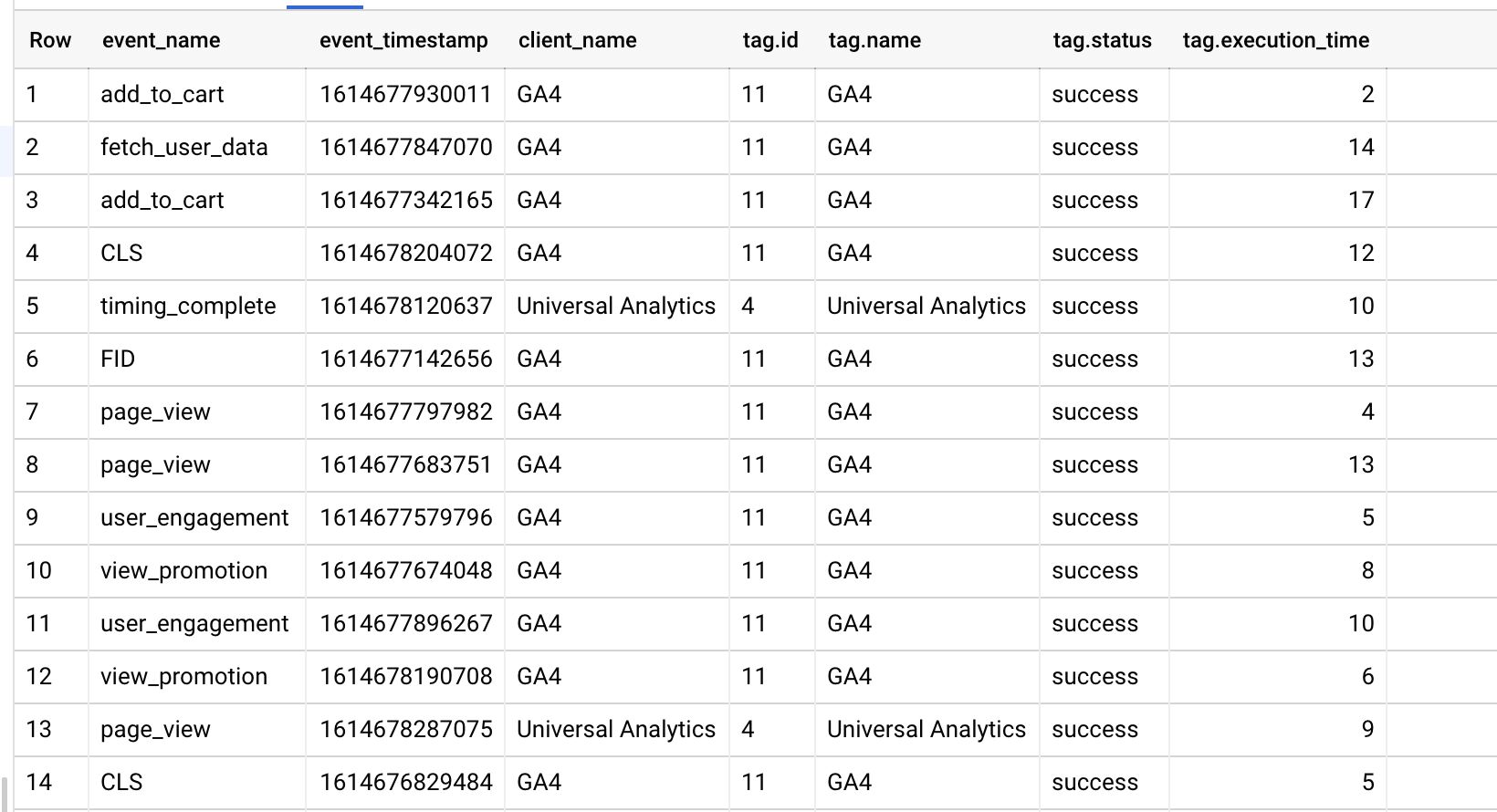
Les schéma est très simple. Il est conçu pour collecter des informations sur le client qui a déclenché le ou les tags, s’ils ont été déclenchés avec succès (ou échoué) et la durée d’exécution du tag.
Vous pouvez l’utiliser pour surveiller de manière proactive les problèmes dans la configuration de votre conteneur de serveur.
Créer le tableau
Avant de commencer, nous devons créer un tableau dans BigQuery. Je recommande d’utiliser le même projet que celui sur lequel votre conteneur de serveur est en cours d’exécution. De cette façon, vous n’avez pas à vous soucier de la configuration de l’authentification, car le conteneur du serveur aura déjà un accès complet à tous les composants cloud exécutés dans le même projet.
Tout d’abord, accédez à BigQuery.
Ensuite, recherchez votre ID de projet dans la navigation et sélectionnez le projet.
Enfin, cliquez CRÉER UN JEU DE DONNÉES pour créer un nouveau jeu de données.
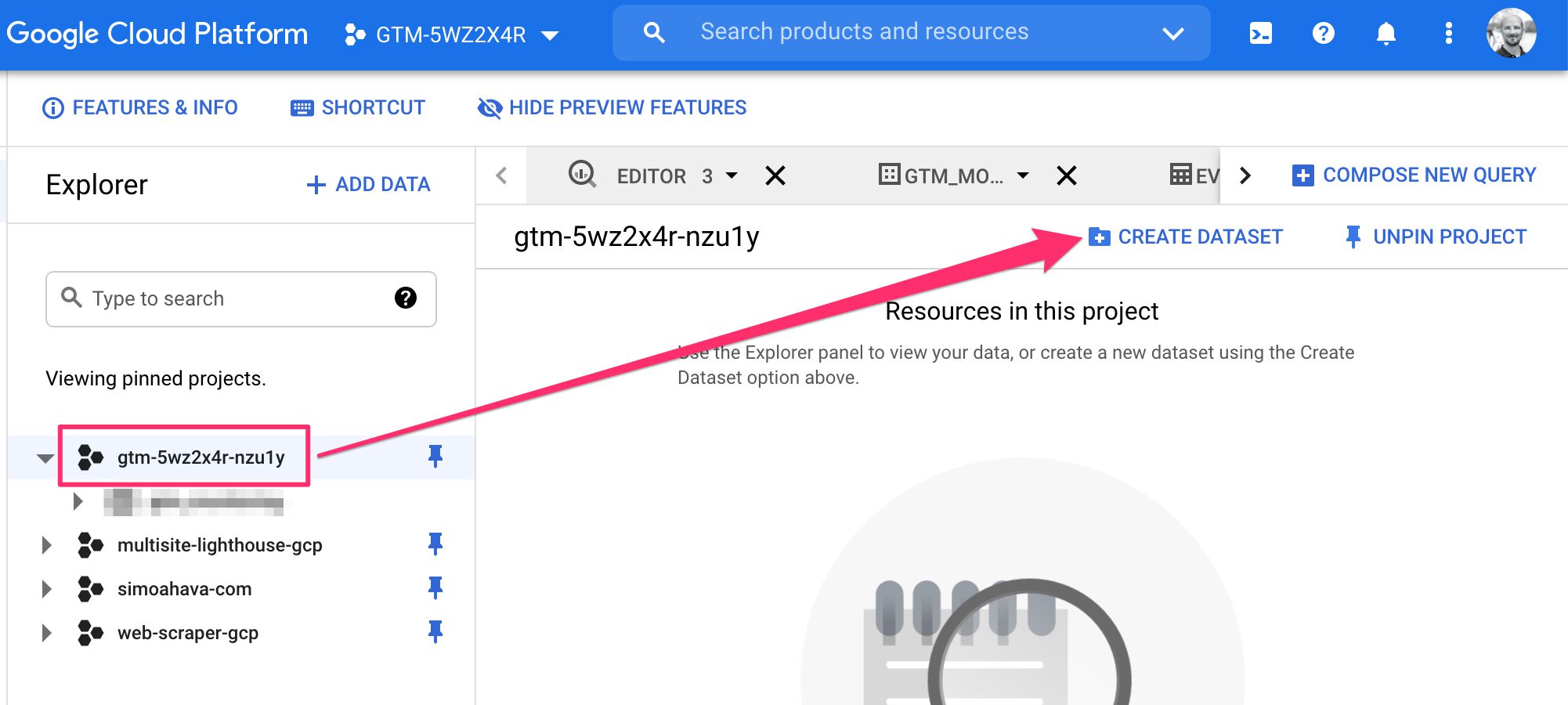
Attribuez un ID à l’ensemble de données, tel que gtm_monitoring, et définissez l’emplacement des données, si vous le souhaitez. Une fois prêt, cliquez sur le Créer un jeu de données bouton.
Une fois le jeu de données créé, assurez-vous qu’il est sélectionné dans la navigation, puis cliquez sur CRÉER UN TABLEAU.
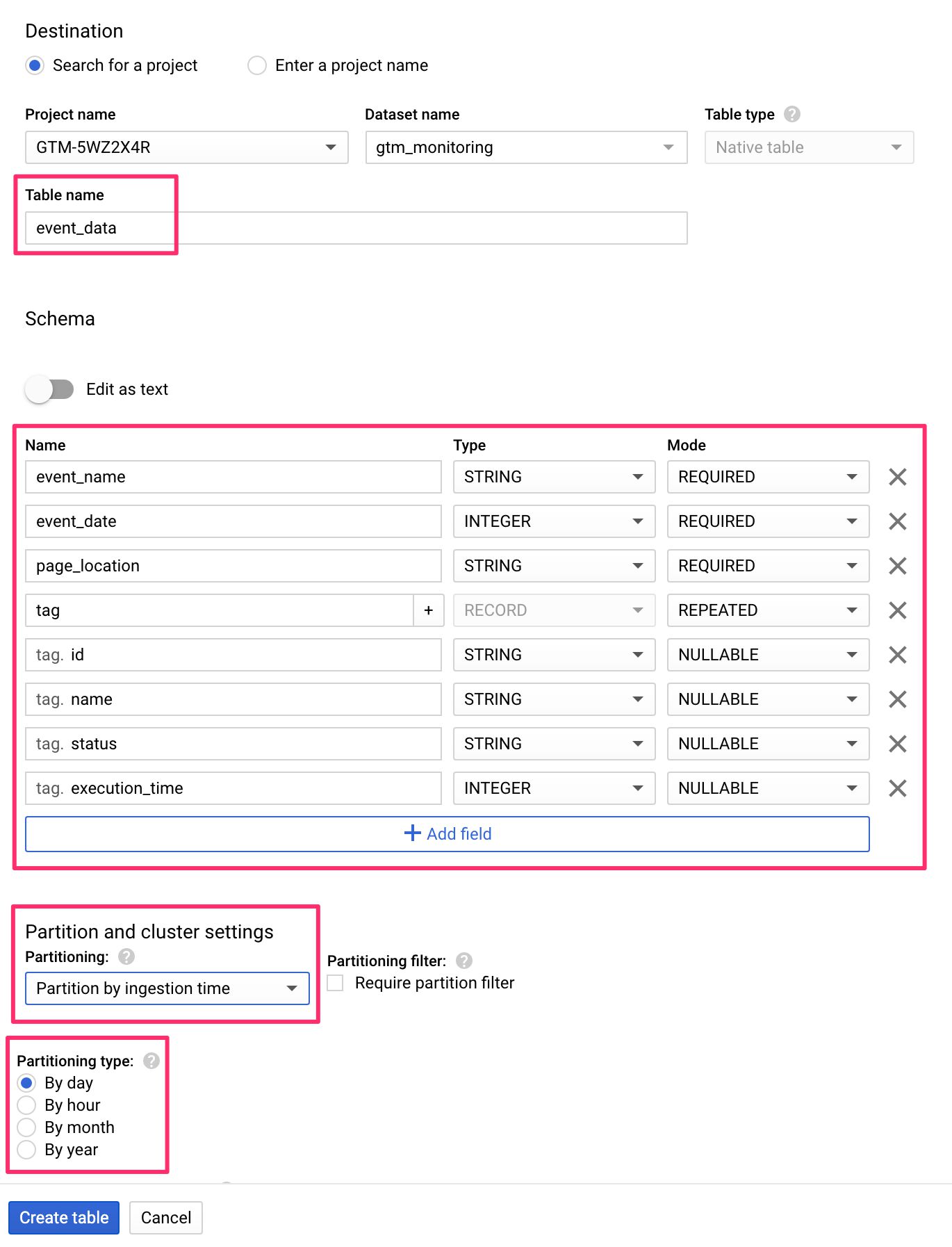
Les trois paramètres que vous voudrez modifier sont Nom de la table, Schémaet Partitionnement.
Met le Nom de la table à tout ce que vous voulez nommer la table, par exemple event_data.
Ensuite, cliquez sur +Ajouter un champ pour commencer à créer le schéma.
Le schéma est essentiellement un plan pour le type de données que la table s’attend à y insérer. Vous devez définir le des champs (ou colonnes) du tableau, qu’elles soient obligatoire ou autre chose, et ce que l’on attend Type de données est.
Consultez la documentation de BigQuery pour plus de détails sur les options dont vous disposez.
Voici le schéma que j’ai choisi pour les données de surveillance :
| Nom de domaine | Taper | Mode |
|---|---|---|
event_name | CHAÎNE | OBLIGATOIRE |
event_timestamp | ENTIER | OBLIGATOIRE |
client_name | CHAÎNE | OBLIGATOIRE |
tag | ENREGISTRER | RÉPÉTABLE |
tag.id | CHAÎNE | NULLABLE |
tag.name | CHAÎNE | NULLABLE |
tag.status | CHAÎNE | NULLABLE |
tag.execution_time | ENTIER | NULLABLE |
Pour Partitionnementj’ai choisi de partitionner par journée, ce qui signifie qu’un suffixe de table est ajouté à chaque ligne avec la date à laquelle les données ont été écrites dans la table. Cela rend l’analyse beaucoup plus facile car vous pouvez très facilement étendre vos requêtes par jour.
Voici à quoi ressemble la configuration finale de la table :
Le modèle de balise
Vous pourrez bientôt trouver le modèle dans la galerie de modèles de la communauté. Pour l’instant, vous pouvez également télécharger le template.tpl fichier en enregistrant cette page avec ce nom de fichier.
Pour charger le modèle dans le conteneur, accédez au conteneur Serveur, sélectionnez Modèleset alors créer un nouveau modèle de balise.
Ensuite, dans le menu de débordement, choisissez Importer.
Localisez le template.tpl fichier que vous avez téléchargé et importez-le à l’aide de la boîte de dialogue système.
Cliquez sur Sauver pour enregistrer le modèle.
Pour comprendre le fonctionnement du modèle, lisez la suite…
Créer la balise de surveillance
Aller à Mots clés dans le conteneur Serveur, puis cliquez sur NOUVEAU pour créer une nouvelle balise.
Maintenant, vous devez configurer la balise. Il y a trois champs que vous devez définir :
- ID de projet – défini sur l’ID de projet GCP du projet où se trouve la table BigQuery. S’il s’agit du même projet que celui qui exécute votre conteneur Server, vous pouvez laisser ce champ vide.
- ID de l’ensemble de données – défini sur l’ID de l’ensemble de données de la table BigQuery.
- Identifiant du tableau – défini sur l’ID de table de la table BigQuery.
Si vous avez suivi les exemples de ce didacticiel, l’ID de l’ensemble de données serait gtm_monitoring et l’ID de table serait event_data.
Ensuite, développez Réglages avancés et Métadonnées de balise supplémentaireset ajoutez une nouvelle ligne de métadonnées avec :
- Clé:
exclude - Évaluer:
true
Voici à quoi devrait ressembler la balise :
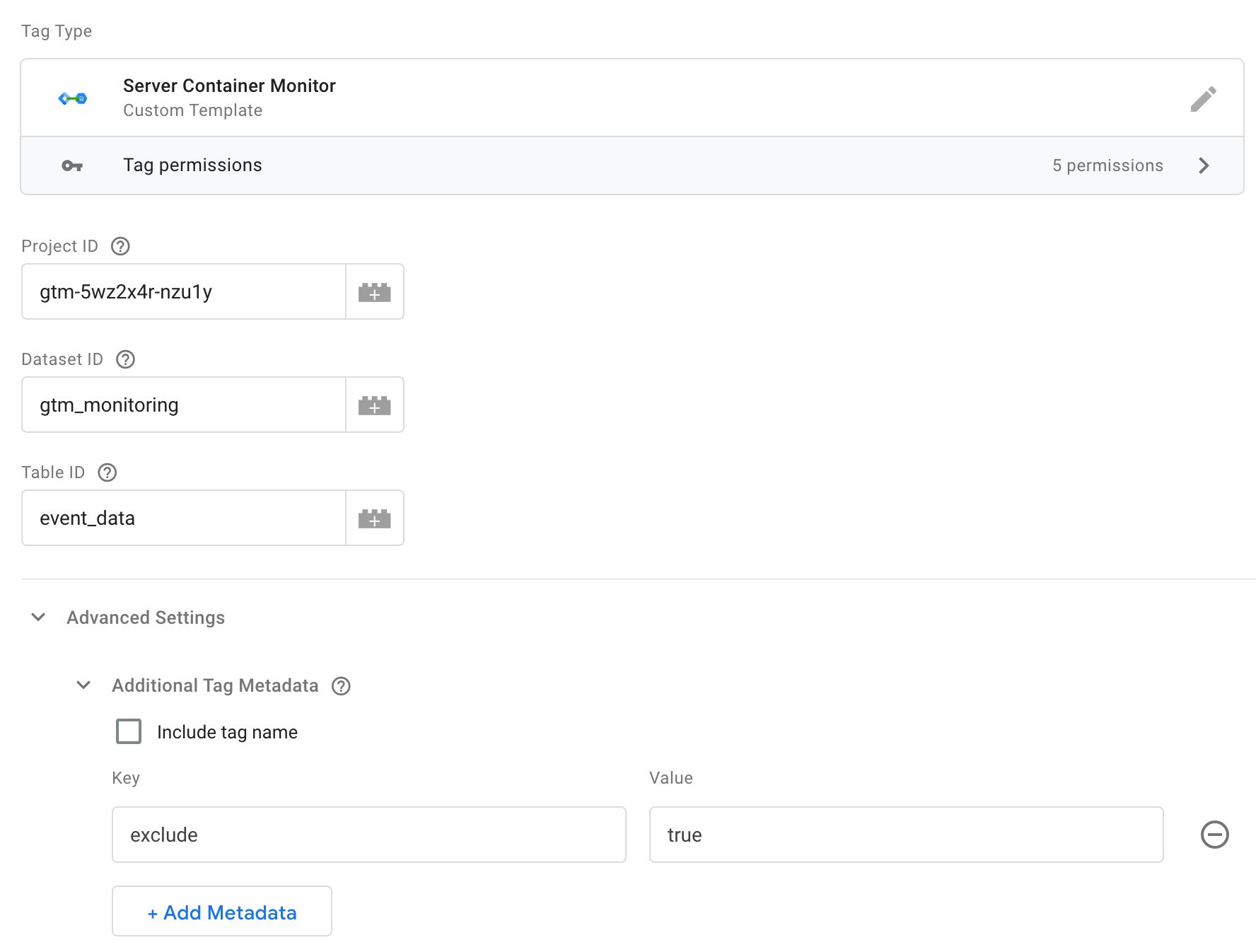
Les ID de projet, ID de l’ensemble de donnéeset Identifiant du tableau sont utilisés par la balise pour s’assurer que les données sont écrites dans la bonne table.
Les exclude clé dans le Métadonnées de balise supplémentaires peut être utilisé pour exclure des balises de la surveillance. Dans ce cas, je trouve que la surveillance de la balise de surveillance elle-même ne fait qu’ajouter au bruit et à la confusion, c’est pourquoi j’ai choisi de l’exclure.
Ajouter le déclencheur
Une fois que vous avez apporté les modifications à la balise de surveillance, vous devez ajouter un déclencheur à cela. C’est assez simple – vous avez besoin d’un déclencheur qui se déclenche pour Chacun car chaque événement a la capacité de déclencher des balises.
Alors allez à Déclencheurs et cliquez NOUVEAU pour créer un nouveau déclencheur.
C’est ce que le Tous les évènements le déclencheur devrait ressembler à :
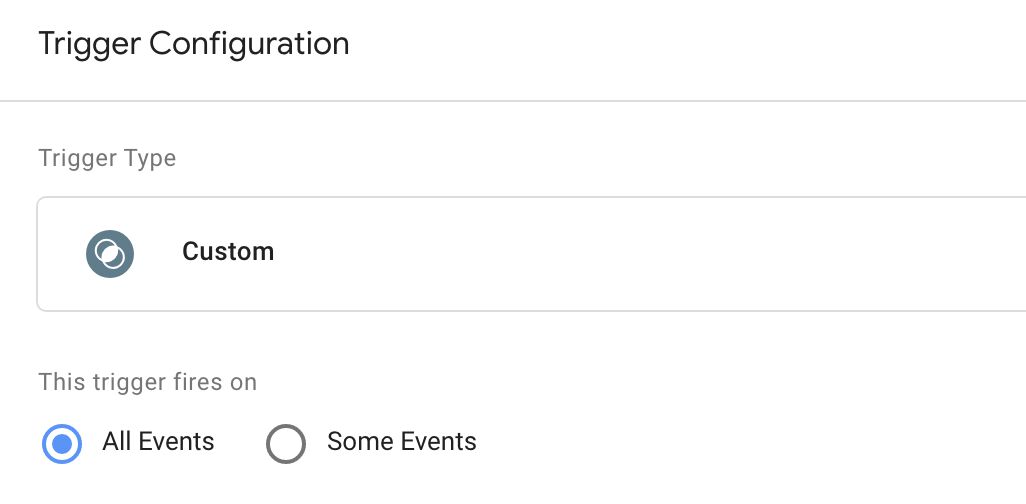
Ajoutez ce déclencheur à votre balise de surveillance, puis enregistrez la balise.
Modifier toutes les métadonnées des balises
La prochaine étape consiste à éditer toutes les balises dans le conteneur. Pour chaque balise, vous devez développer Métadonnées de balise supplémentaires de nouveau.
Ici, vous devez vérifier Inclure le nom de la baliseet dans le Clé pour le nom de la balise champ que vous devez saisir name. Ainsi:
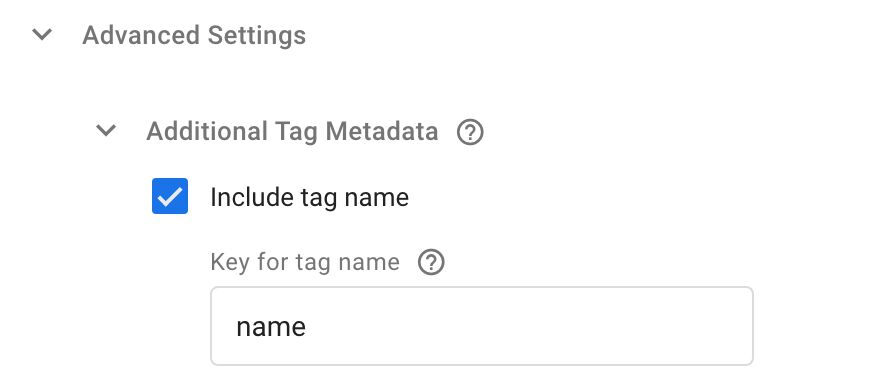
Tous les champs de Métadonnées de balise supplémentaires sont transmis au rappel d’événement qui est défini dans le modèle de balise de surveillance lui-même. Ce rappel est exécuté une fois tous les balises de cet événement sont terminées et l’objet de métadonnées fournit des détails supplémentaires sur les balises elles-mêmes.
Si vous le souhaitez, vous pouvez ajouter encore plus de paires clé-valeur aux métadonnées de balise. Il vous suffit de modifier le modèle de surveillance pour les ajouter à l’appel de l’API BigQuery. Et, bien sûr, vous avez besoin d’un schéma de table BigQuery qui accepte les nouvelles valeurs.
Vérifier les résultats dans BigQuery
À ce stade, vous devriez avoir les éléments suivants :
- Vous avez importé le modèle depuis mon dépôt (ou la galerie).
- Vous avez créé une nouvelle balise de surveillance avec le modèle.
- Vous avez configuré la balise de surveillance avec les détails de votre table BigQuery.
- Vous avez ajoutée les Tous les évènements déclencheur à la balise de surveillance.
- Vous avez édité toutes les balises du conteneur et vous leur avez ajouté le nom de la balise en tant que métadonnées supplémentaires.
Vous pouvez maintenant prévisualiser le conteneur (recommandé) ou simplement le publier. Si vous empruntez l’itinéraire Aperçu, vous devriez voir le BigQuery success! message dans le Onglet Console du mode Aperçu lorsqu’un événement est sélectionné :

Si vous voyez autre chose, les messages d’erreur devraient vous indiquer quel est le problème (voir ce chapitre pour plus de détails).
Vous pouvez également vérifier les données dans BigQuery. Pour ce faire, la méthode la plus simple consiste à accéder au tableau lui-même, puis à cliquer sur Aperçu.

Si vous voyez des lignes ici, cela signifie que cela fonctionne !
Vous avez maintenant construit un système de surveillance simple. Bien qu’il s’agisse principalement d’une preuve de concept, vous pouvez réellement utiliser cette configuration pour voir si les balises signalent systématiquement un échec. De même, il devrait vous alerter s’il y a des événements où aucune balise ne se déclenche (même s’ils le devraient), ou s’il y a des temps d’exécution déraisonnablement longs avec vos balises.
Et c’est tout pour cette simple procédure pas à pas ! Il est maintenant temps de plonger dans la conception de l’API elle-même.
L’API BigQuery
Pour utiliser l’API, vous avez besoin soit d’un Client ou un étiqueter modèle. Si vous n’êtes pas familier avec les modèles, consultez ces ressources :
- Guide des modèles personnalisés pour Google Tag Manager
- Créer un client Universal Analytics (YouTube)
Remarque, seul un écrivez L’API a été publiée jusqu’à présent. Nous attendons avec impatience un lire API, afin que les données puissent également être extraites de BigQuery.
L’API elle-même est assez simple, mais pour le moment, elle comporte une mise en garde : la table dans laquelle vous voulez écrire doit déjà exister. Contrairement à certains autres clients de l’API BigQuery, l’API de modèle personnalisé ne crée pas automatiquement de table pour vous s’il n’en existe pas déjà une.
C’est bon pour le contrôle mais mauvais pour la flexibilité. Il est possible que cela change à l’avenir. Mais jusqu’à ce que ce soit le cas, vous devez avoir une table BQ prête avec un schéma en place également.
L’API s’appelle ainsi :
// Load the BQ API const BigQuery = require('BigQuery'); BigQuery.insert(connectionInfo, rows, options, onSuccess, onFailure); L’objet connectionInfo
Le premier paramètre est un connectionInfo objet, et il ressemble à ceci :
{ projectId: 'gtm-abc123-z1def', datasetId: 'gtm_monitoring', tableId: 'event_data' } Voici les clés que vous devez utiliser dans l’objet :
| Clé | Valeur de l’échantillon | Obligatoire | La description |
|---|---|---|---|
projectId | gtm-abc123-z1def | Non* | Défini sur l’ID de projet Google Cloud où se trouvent l’ensemble de données et la table BigQuery. Vous pouvez également l’omettre de l’appel d’API (voir ci-dessous pour plus d’informations). |
datasetId | gtm_monitoring | Oui | Défini sur l’ID d’ensemble de données de l’ensemble de données BigQuery qui héberge la table. |
tableId | event_data | Oui | Défini sur l’ID de table de la table BigQuery. |
projectId est facultatif, mais seulement dans des circonstances précises. Si l’appel d’API n’a pas projectId inclus, alors vous devoir met le Autorisations pour BigQuery afin que l’ID du projet soit Soit * ou alors GOOGLE_CLOUD_PROJECT.
Autorisations
Lorsque vous définissez l’autorisation d’ID de projet sur GOOGLE_CLOUD_PROJECTl’ID du projet est dérivé d’une variable d’environnement nommée GOOGLE_CLOUD_PROJECT. La bonne nouvelle est que si vous exécutez ce conteneur sur Google Cloud (comme c’est le cas par défaut), la variable d’environnement est automatiquement renseignée avec l’ID de projet actuel.
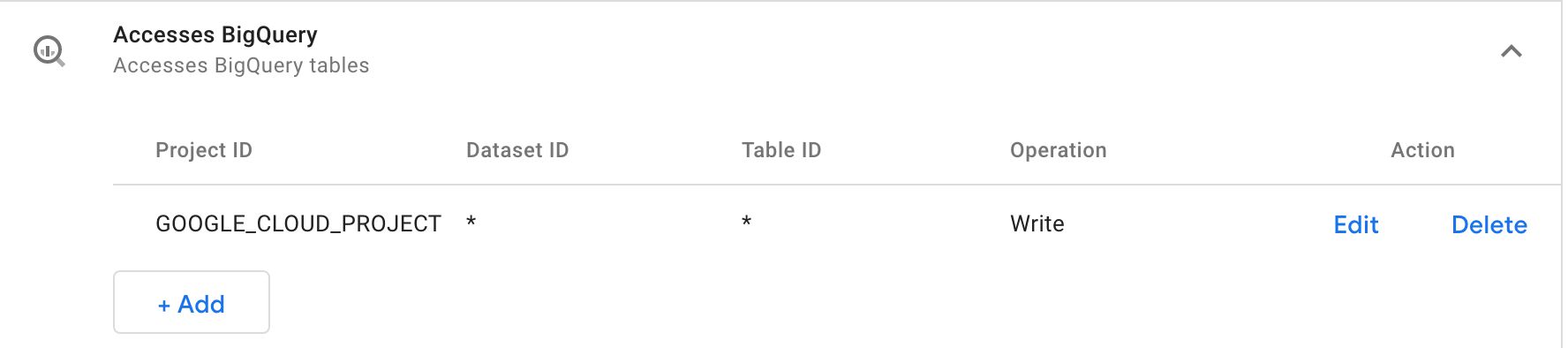
Si vous souhaitez envoyer les données à une table en dehors du projet actuel, il est plus simple d’ajouter simplement l’ID du projet à la liste des autorisations ou d’utiliser simplement le caractère générique (bien que le premier soit recommandé par rapport au second).
Vous pouvez également utiliser des caractères génériques pour l’ID de l’ensemble de données et l’ID de la table, mais vous ne devez le faire que si vous concevez le modèle pour le partager via la galerie de modèles de la communauté.
Les rows déployer
Le deuxième paramètre du BigQuery.insert l’appel est le rows déployer.
Et c’est là que ça se complique.
Les rows déployer devoir respectez le schéma de la table si vous voulez que les données soient écrites correctement. Vous devez essayer d’utiliser les types et formats requis par le schéma de table BigQuery lors de la création des objets dans le rows déployer.
Par exemple, considérons un schéma comme celui-ci :
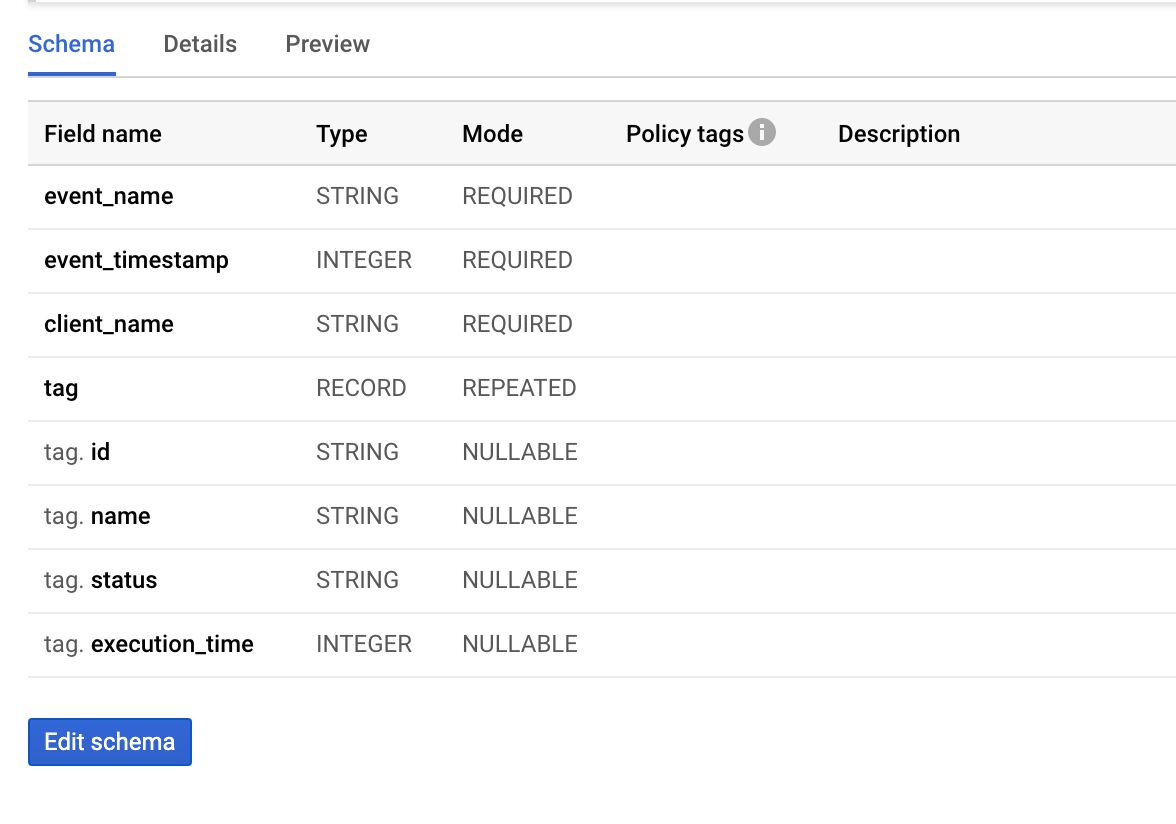
Pour créer une ligne valide pour ce schéma, l’objet ressemblerait à ceci :
[{ event_name: 'page_view', // String, required event_timestamp: '1614628341914', // Integer, required client_name: 'GA4', //String, required tag: [{ // Record, repeated id: '1', // String, nullable name: undefined, // String, nullable status: 'success', // String, nullable execution_time: '3' // Integer, nullable }, { id: '3', // String, nullable name: 'GA4', // String, nullable status: 'success', // String, nullable execution_time: '10' // Integer, nullable }] }] Comme vous pouvez le constater, chaque propriété définie dans un objet de ligne correspond à une clé dans le schéma BigQuery, et les valeurs doivent correspondre aux types attendus.
Remarque : “Integer” fait référence au format de données, pas au type JavaScript. Il peut donc être envoyé en tant que type Number ou en tant que type String comme dans l’exemple ci-dessus.
Les choses les plus difficiles à faire correctement sont généralement enregistrements répétés. Il est peut-être plus facile de penser à cela en termes de JavaScript. UN enregistrement répété est essentiellement un tableau d’objets. Ou un liste des dictionnaires si la langue vernaculaire Python vous convient mieux.
Dans tous les cas, l’objet envoyé à la table devoir conforme au schéma, sinon vous risquez de rencontrer des erreurs ou d’obtenir des données inégales.
Les options chose
Vous pouvez contrôler ce que fait l’API lorsqu’elle rencontre des appels non valides.
Les options object est le troisième paramètre de BigQuery.insert méthode, et il a les clés suivantes:
| Clé | Valeurs possibles | Défaut | La description |
|---|---|---|---|
ignoreUnknownValues | true / false | false | Si réglé sur truepuis les lignes qui ont des valeurs qui font ne pas conformes au schéma sont acceptées, mais les valeurs inconnues sont ignorées lors de l’écriture. |
skipInvalidRows | true / false | false | Si réglé sur true Alors tout valide les lignes de la demande sont insérées dans la table, même s’il existe également des lignes non valides dans la demande. |
Ce que vous choisissez pour ces options dépend du type de données que vous souhaitez collecter. Si vous définissez ignoreUnknownValues pour truevous risquez de vous retrouver avec une table inégale, car les valeurs attendues risquent de manquer dans la table.
Si vous définissez skipInvalidRows pour trueil peut être difficile de déboguer les problèmes, car les requêtes sont autorisées à se terminer même si elles contiennent des lignes non valides.
Les onSuccess rappeler
Vous pouvez éventuellement passer une méthode en tant que onSuccess rappeler. Cette méthode est invoquée sans aucun argument et vous pouvez l’utiliser pour exécuter du code après l’insertion réussie des lignes.
... const onBigQuerySuccess = () => { log('BigQuery rows inserted successfully!'); data.gtmOnSuccess(); }; BigQuery.insert(connectionInfo, rows, {}, onBigQuerySuccess, data.gtmOnFailure); Les onFailure rappeler
Vous pouvez éventuellement passer une méthode en tant que onFailure rappeler. Cette méthode est invoquée lorsqu’une erreur se produit et un tableau de toutes les erreurs qui se sont produites est automatiquement transmis à cette méthode.
... const onBQFailure = (errors) => { log('BigQuery failure!'); log(errors); data.gtmOnFailure(); }; Notez que vous n’avez généralement pas besoin de les consigner explicitement, car les erreurs BigQuery s’afficheront dans l’onglet Console du mode Aperçu et dans votre
stdoutjournaux indépendamment.
Si l’erreur s’est produite parce que l’insertion ne s’est pas produite du tout, par exemple lorsque vous essayez d’insérer une ligne dans une table inexistante, l’erreur est simple :
[{ reason: 'invalid' }] Si, cependant, il y a une erreur dans l’insertion elle-même, le tableau d’erreurs est plus complexe. Pour chaque erreur rencontrée, un objet est ajouté au tableau. Cet objet a deux clés :
errors est un tableau avec un seul objet qui a le reason clé. Cette clé est réglée sur raison pour laquelle l’erreur s’est produite (par exemple "invalid").
row est un objet qui décrit la ligne elle-même où l’erreur s’est produite.

Dans l’image ci-dessus, Trois des erreurs ont été rencontrées. La première erreur était due à une valeur non valide envoyée avec l’appel. En raison de skipInvalidRows étant fixé à false (la valeur par défaut), cela entraîne l’arrêt de l’exécution de l’insertion et toutes les lignes restantes génèrent une erreur avec la raison stopped.
Notez qu’il est complètement facultatif d’utiliser le onFailure callback, mais cela peut être une très bonne idée si vous voulez aller au fond des données manquantes ou erronées dans votre table !
Authentification
Tant que votre conteneur de serveur s’exécute dans le même projet GCP que la table BigQuery, tout est prêt. Vous n’avez rien à faire de spécial en termes d’authentification, car le compte de service par défaut d’App Engine dispose d’un accès complet à toutes les tables BigQuery ajoutées au projet.
Si vous souhaitez écrire dans une table BigQuery dans une autre projet GCP, vous devez effectuer les opérations suivantes :
- Localisez le Compte de service par défaut App Engine (sous API et services / Identifiants) du projet de conteneur de serveur.
- Copiez l’adresse e-mail de ce compte de service dans le presse-papiers.
- Dans le JE SUIS du projet GCP avec la table BigQuery, ajoutez un nouveau membre.
- Définissez l’adresse e-mail du membre sur l’adresse e-mail du presse-papiers.
- Définissez le rôle de ce nouveau membre sur Éditeur de données BigQuery.

Comptes de service dans le projet de conteneur de serveur.
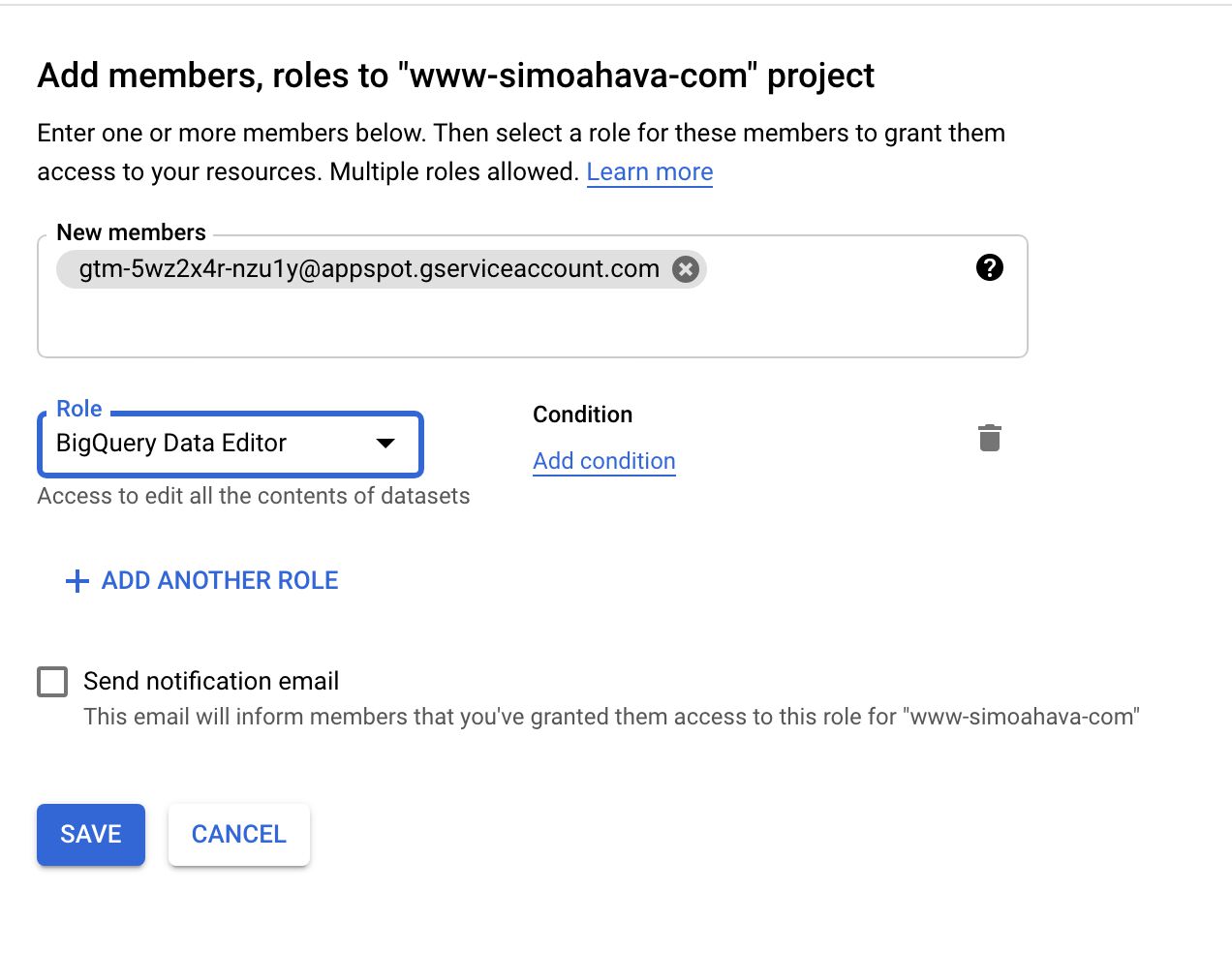
Création d’un nouveau membre dans le projet avec la table BigQuery.
En d’autres termes, vous autorisez le projet GCP du conteneur de serveur à modifier les ensembles de données BigQuery dans le projet cible.
Vous pouvez, bien sûr, créer un compte de service dédié uniquement à cet effet pour éviter de donner un accès trop large au projet de conteneur Server. Mais c’est un moyen facile de faire fonctionner l’intégration.
Si vous souhaitez authentifier un non-GCP source pour écrire dans BigQuery, cela devient un peu plus délicat. Je vous recommande de suivre le guide de configuration manuelle pour ce faire.
Résumé
Vous pouvez ignorer tout J’ai écrit dans cet article et je me réjouis juste d’une seule chose:
Les conteneurs de serveur ont désormais accès à Google BigQuery !!!
Je ne peux pas exagérer à quel point c’est important. Pouvoir communiquer avec d’autres composants du cloud sans avoir à passer par des liaisons de compte de service compliquées et des schémas d’authentification est très agréable. Mais pouvoir utiliser l’un des entrepôts de données les plus puissants et les plus perturbateurs qui existent est la vraie affaire.
Avec l’API BigQuery, le ciel est la limite de l’innovation.
Que diriez-vous d’écrire les requêtes GA4 entrantes directement dans Google BigQuery, au lieu de passer par Google Analytics ?
Que diriez-vous de consigner les erreurs et d’autres données de surveillance dans une table BigQuery pour une analyse plus détaillée et plus économique ultérieurement ?
Que diriez-vous d’écrire toutes les transactions collectées par Facebook dans une table BigQuery pour une déduplication ou un débogage ultérieur ?
Il y a juste tellement vous pouvez faire avec Google BigQuery. J’ai hâte de voir ce que les membres de la communauté de conception de modèles vont proposer.
J’espère que cela ne fait que préfigurer l’introduction d’autres API Google Cloud également. Souhaitons un Stockage en ligne API (pour les opérations rapides de lecture et d’écriture de fichiers), et un Pub / Sous-marin API (pour initialiser d’autres processus cloud), par exemple.
J’espère également que BigQuery obtiendra un read API aussi, bientôt. Ayant insert est génial, mais si nous pouvions utiliser BigQuery pour enrichir réellement les flux de données de notre conteneur de serveur, cela rendrait la configuration encore plus riche et plus flexible.
Que pensez-vous de l’API BigQuery ? Quel genre de choses pourriez-vous envisager de faire avec ?




